整体架构
宏观上可以将Kafka分成三个部分:生产者、中间服务层、消费者
中间服务层相当于一个“消息中转站”,但不同之处在于,中间服务层会将消息持久化存储
中间服务层由多个部件构成:
- broker:可以理解为是一个节点,即运行Kafka程序的服务器
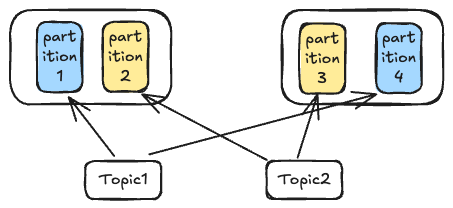
- topic:对消息进行逻辑分类的粗粒度单位,可用于实现负载均衡、消息并行处理。消费者订阅某一个主题进行消费。生产者向指定的主题写入消息
- partition:消息上物理上存储的空间,一个partition对应着一个topic,一个topic可以有多个partition。partition对于生产者和消费者是透明的、无法感知的。
- 每个partition存储着有序、不可变的消息序列
- partition可被独立读写
broker、topic、partition三者之间的关系如下:
Topic
在Kafka中,Topic就是一个主题,属于逻辑上的概念,并不存在任何一台物理设备上。作为使用者,我们可以将同业务的消息放入同一个topic,例如秒杀业务、售票业务等,通过这个逻辑上的概念,可以粗粒度地将数据消息进行分片,分门别类地处理消息。
Partition
对数据进行逻辑Topic分区后,一个业务的数据量可能仍然庞大,为了对数据进一步分而治之,设计Kafka的大佬决定将Topic的数据实际物理存储在一个个Partition中。Partition就相当于对粗粒度划分的数据再进行一次细粒度区分。由于Topic是一个逻辑上的概念,并不存在于某一个具体的broker上,因此在集群模式下,同一个Topic下的多个Partition是独立的,完全可以在不同的broker上。
分片的好处:
- 提高写入性能,不同的partition分布在不同的broker上,可以实现并行写入,提高了系统吞吐量
- 提高消费者并发度,因为有了不同的分片,不同的消费者可以对不同的分片同时消费
- 提高了Kafka水平扩展能力
- 提高了系统的容错能力,引入partition后,同一个 Topic下不同partition中的数据解耦合,即使一个partition崩溃了,也不影响其他partition运作
一个Partition就相当于一个队列,最新的数据被写在队列的末尾,即同一个Partition下的数据是有序的,但综合来看,同一个Topic下的所有Partition中的数据是无序的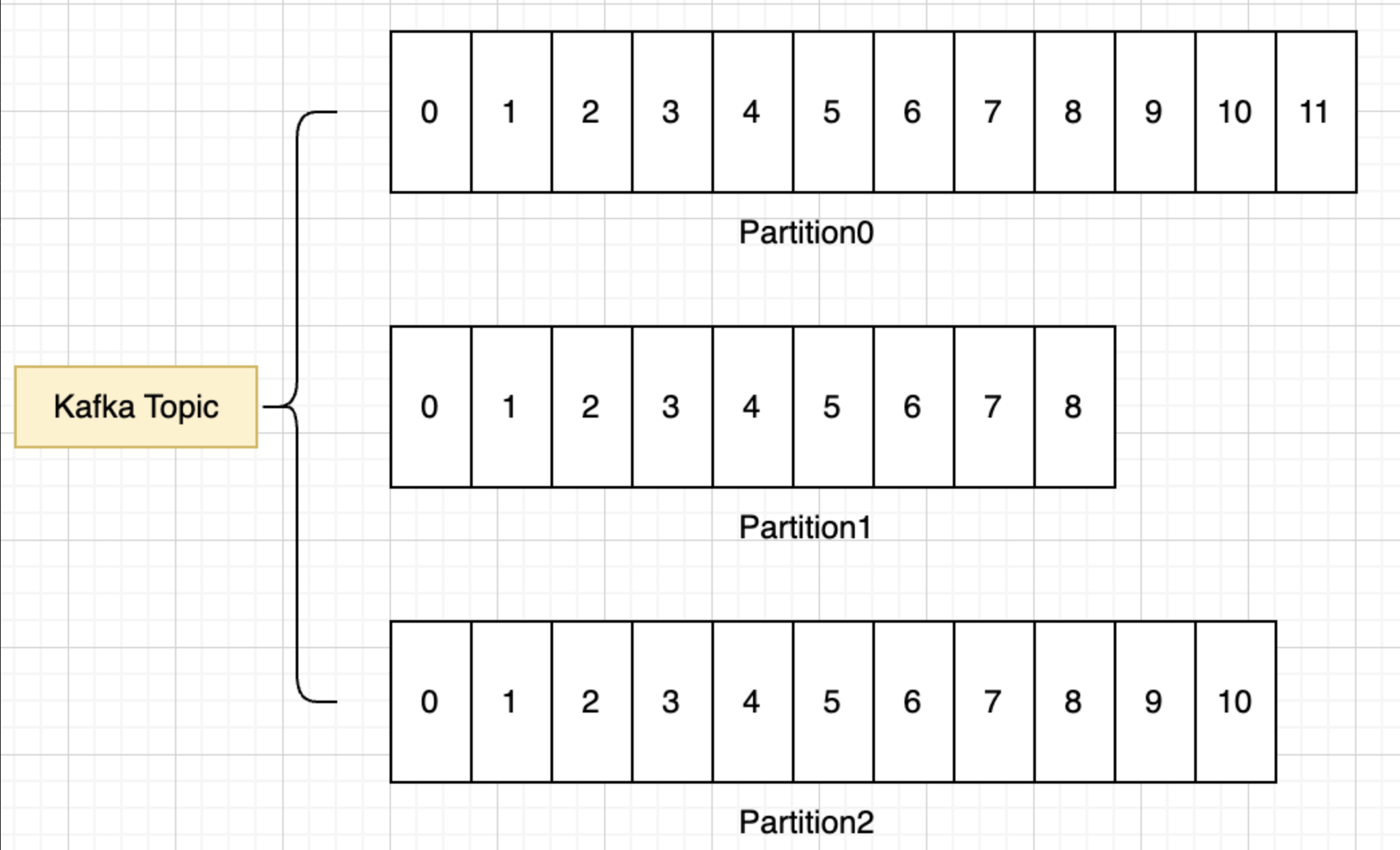
由于Partition对于生产者是透明的,那么生产者向一个Topic写入数据,数据最终会流向何处呢?
如果生产者向Topic发送消息时没有指定Key,那么Kafka服务就会默认采取轮询Partition的方式将数据写入到Partition中。
如果生产者指定了发送的Key,那么消息就会被写入到将Key进行哈希过后对应的Partition中
Broker
Broker实际就是一个运行Kafka程序的服务器节点,Broker需要提供如下功能:
- 接受来自客户端的连接
- 支持客户端查询Kafka集群的信息,比如查询其他Broker信息
- 响应来自客户端的命令请求
- 存储消息,即将消息持久化存储在本地服务器上
在集群部署模式下,每一个Broker都有唯一的ID标识自己身份。Partition是存放在Broker节点上的,一个Partition对应一个Broker,一个Broker可能存放着多个Partition
针对于一个Topic下的多个Partition,需要先随机选取一个Broker(比如是Broker10)存放Partition_0,接着按照Broker的ID顺序依次存放Partition,即Broker11存放Partition_1、Broker12存放Partition_2,以此类推。
前文提及了,消费者在发送消息时可以指定Key,相当于将消息发送到指定的Partition上。那么客户端是如何在Kafka集群中快速找到目标Partition所在的Broker节点呢?
通常客户端连接集群有三种方式:
- 引入代理,代理和众多Broker打交道
- 重定向,客户端发送命令到某一个节点上,如果该节点不是目标节点,那么该节点会告知客户端木笔哦节点具体地址(Redis)
- 查询路由表,客户端先查询路由表,直接向目标节点发送请求命令(Kafka)
Kafka选择第三种方式的一个契机是,在Kafka集群中,每一个Broker都支持客户端查询Kafka集群的信息,即每一个Broker都知晓其他Broker的信息。这些信息都被维护在每一个Broker的路由表中,了解了这一点,客户端发送读写命令的过程就呼之欲出了:
- 任意访问一台Broker
- 从这台Broker中获取路由表
- 根据规则找到目标Partition,在路由表中找到哪个Broker上存有目标Partition,最后发送读写命令
- 找Partition的规则就是上文讲的轮询或哈希Key规则
生产者Producer
生产者发送一条消息需要历经三个步骤:
- 构建消息:将需要发送的信息打包成Kafka消息结构
- 序列化消息:将消息序列化成二进制数据,以便在网络中传输
- 寻找Broker:根据规则找到目标分区,接着依据路由表将消息发送到Partition对应的Broker
构建消息
生产者需要将发送的信息打包成Kafka消息结构,接下来就详细看看消息结构的具体组成: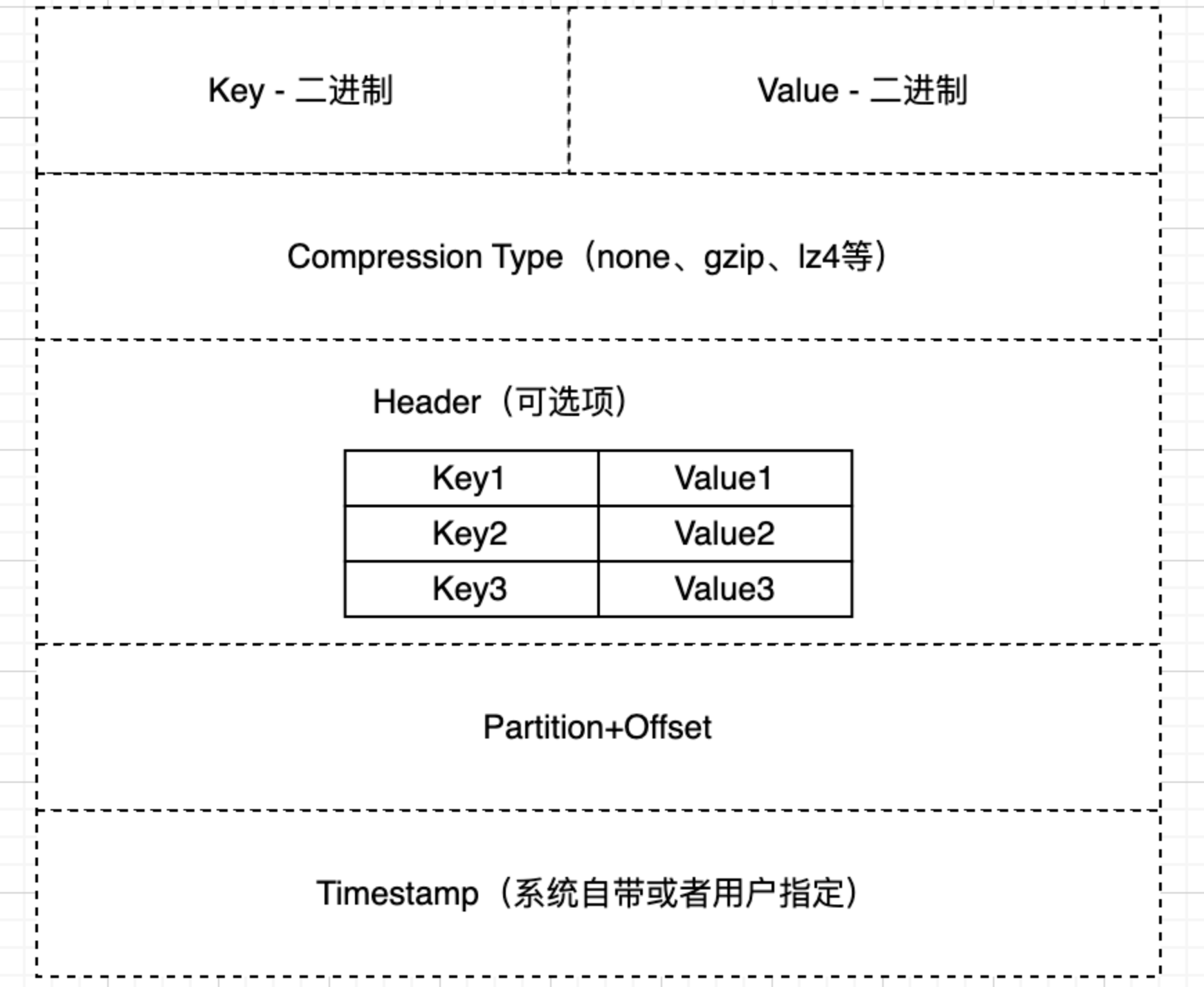
- Key:根据Key的哈希值(取模)确定发送到Topic下的哪一个Partition上,一般是字符串类型,最终会被序列化为二进制数据
- Value:实际发送的数据
- Compression Type:指定压缩算法,该字段表明采用什么压缩算法对数据进行压缩,枚举值:None、gzip、lz4等
- Header:生产者额外想传输的数据就放在Header中,比如TraceID
- Partition+Offset:该字段在生产出来的时候是空的,消息发送到Kafka服务端后才会将具体的分区、偏移量写入该字段。Topic + Partition + Offset唯一确定一条消息
序列化
序列化就是将消息从常规类型转换至二进制类型,以在网络中传输
发送模式
在Go、Java的SDK中提供了三种消息发送模式:
- 同步发送,生产者发送消息后,执行阻塞操作,等待Kafka服务端返回发送消息成功或异常结果。适用于生产者需要确保成功发送消息才能执行后续操作的场景。
- 发了就忘,生产者发完消息就继续执行后续操作,不理会消息是否发送成功,也不采取措施应对发送异常
- 异步发送,生产者发送消息的同时注册回调函数,不执行阻塞操作,而是继续执行后续的操作。当Kafka服务端返回发送消息的结果后,执行对应回调函数的内容
三种发送模式实际上就是高性能和可靠性之间的权衡。同步发送模式可靠性强,但是效率不高,适用于保持数据一致性的场景;发了就忘性能高,可是不保证可靠性,因此适合在要求高性能的场景下使用;异步发送就是在二者之间的折中办法,使用于在需要时处理消息发送失败的情况
消费者Consumer
和生产者一样,消费者也需要集成Kafka客户端库,通过接口向Broker获取消息进行消费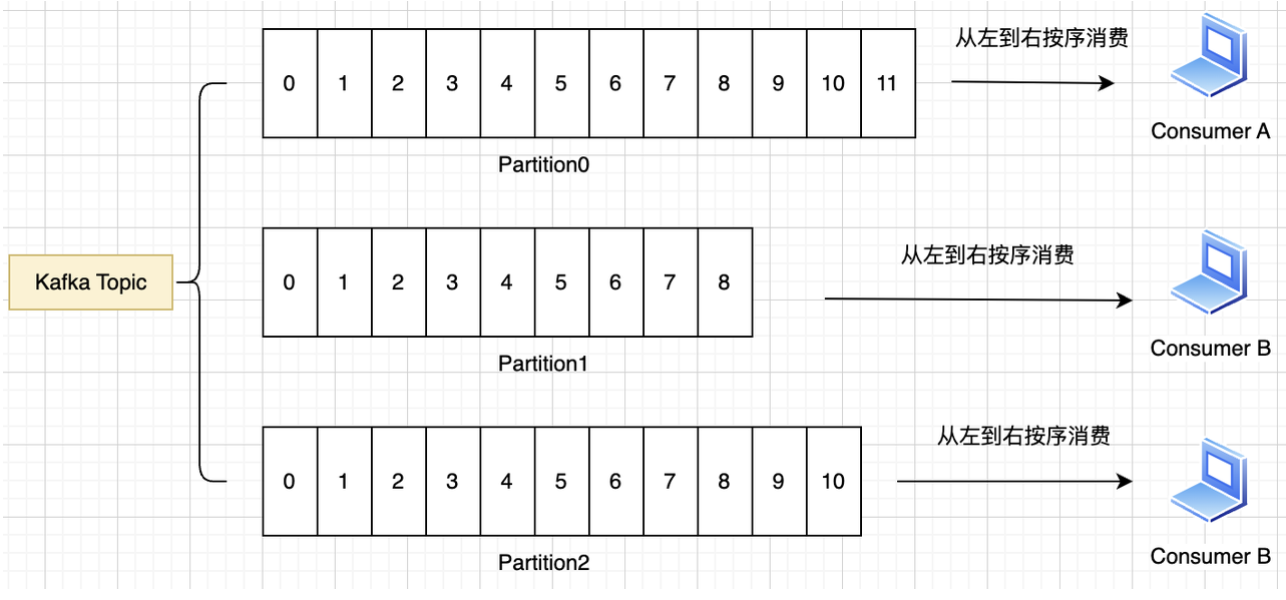
通过上图可得出一下结论:
- 不同的消费者可以在同一时刻对同一Topic进行消费
- 一个消费者可以在同一时刻对一个Topic下的不同Partition进行消费
- 一个消费者同时消费多个Partition是无法保证消息有序性的
- 一个消费者只消费一个Partition,消费顺序即生产顺序,是有序的
拉还是推?
消费者消费消息是通过拉模式进行的,也就是说,消费者先向Broker发送拉取消息的信号,接着Broker再将消息发送给消费者,而不是Broker主动向消费者推送消息。
选择这种拉模式的主要原因在于,消费者可以根据自身的资源利用率(CPU、内存等)适时地向Broker拉取消息,调节消费速度,避免因消费速度不合适导致资源浪费或超载
消费者Offset
在Partition中,位于Offset之前的消息都已经被消费过了,而之后的消息则没有被消费。消费者组每消费完一个消息后,就向Broker提供该消息的Offset,表示该消息已经消费过了。消费者下一次拉取的消息就是Partition中Offset的下一位。消费者完成消费后,就将该消息的“Partition + Offset”字段信息发送给Broker,由Broker负责更新对应Partition的Offset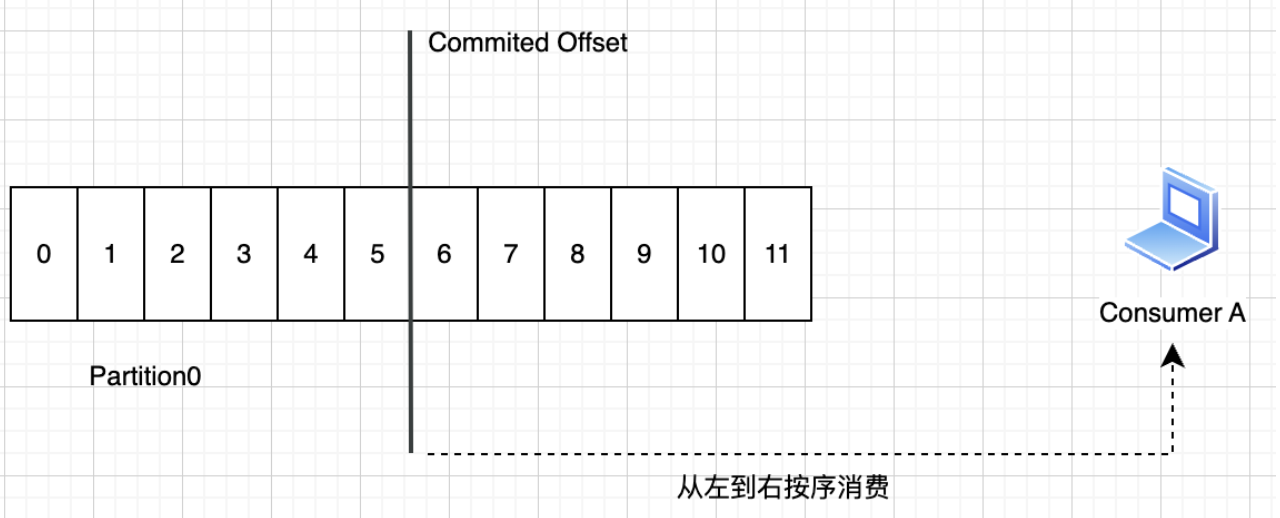
主动提交和被动提交
消费者组提交Offset分为两种方式:
- 被动提交
- 主动提交
被动提交就是定时周期性地向Broker提交最新已处理的消息。但是这种提交方式存在一致性问题,例如消费者正在处理offset为5的消息,此时发生了被动提交,需要告知Broker将Offset更新为5,但实际上offset为5的消息还没有完全处理完。如果此时发生了崩溃重启,那么该消息就会被丢失。
手动提交则是一种更为稳妥的方式,当某条消息彻底处理好后,再主动向Broker提交消息,避免出现不一致的情况。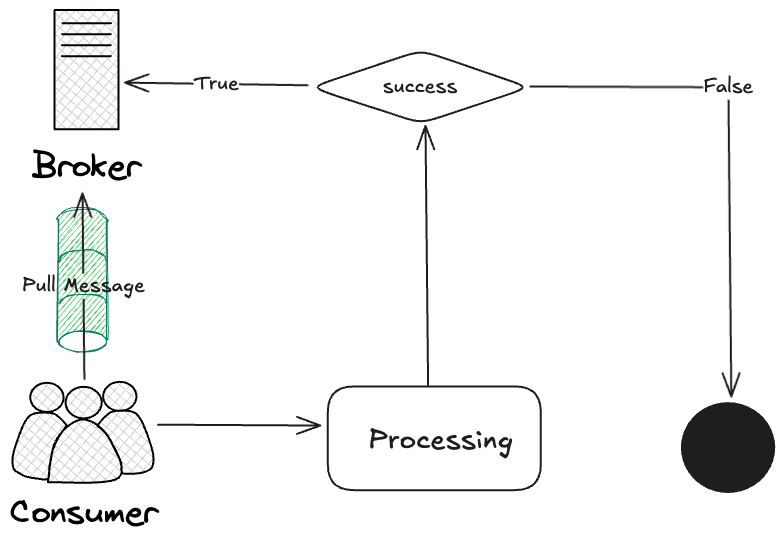
消费者组ConsumerGroup
消费者组实质就是由多个消费者组成的集合,一个消费者组由一个GroupID唯一标识。
多个消费者组成消费者组,那么这些消费者必须有一些约束:
- 在同一个消费者组中,一个Partition只能分配一个消费者
- 同一个消费者组中,可以分派多个消费者
- 不同消费者组可以同时消费同一个Topic
消费者组在消费者方面进行了水平扩容,提高了消费能力。
消费者组咋眼一看没多大用处,实际上,消费者组带来的最大便利在于对分区的封装性,一个消费者组可以自动完成Re balance操作,使得Partition对于消费者是透明的。反之,消费者每次拉取消息都要指定Partition,这就导致Partition和消费者耦合在一块,Partition数量发生变动,消费者方面的代码就要随之变动
消费者组分区分配策略
partition.assignment.strategy字段可以配置消费者组中多个消费者对于分区分配的规则:
- Range Assignor:基于范围的分配策略
- Round Robin Assignor:基于轮询的分配策略
- Sticky Assignor:优先保持当前的分配状态,尽量减少Rebalance过程中分区的移动
- CooperativeSticky Assignor:基本和Sticky Assignor策略一致,但是区别在于该协议将原来一次行对一大片分区进行Rebalance改为多次小规模的Rebalance操作,即渐进式Rebalance
Rebalance机制
Rebalance机制用于确保数据在消费者组中尽可能地负载均衡
触发Rebalance的三个时机:
- 加入新的消费者
- 消费者减少,不论是正常关闭还是崩溃
- Topic下的Partition数量发生变化
再平衡的步骤
再平衡操作需要经历五个阶段:
- 暂停消费,消费者需要暂停正在进行的消费,防止重新分配过程中出现数据丢失或重复问题
- 触发再分配,由消费者组协调器Group Coordinator(通常是一个Broker)触发再平衡
- 分配分区,消费者配合协调器根据当前消费者和分区数量,重新分配主题的分区
- 获取分配信息,重新分配完成后,消费者会从协调器拿到新的分区分配情况
- 恢复消费,消费者收到新的分配后,恢复消费,开始处理新分区
上文提到有四种消费组分区分配策略,这四种分配策略可以依据是否产生STW问题分为Eager和Incremental两种再平衡策略。其中前三种方案都是Eager策略,因为这三种分配策略在暂停消费者阶段会停止所有的消费行为,而Cooperative Sticky方式则只会暂停部分消费者,未被暂停的消费者仍能继续消费行为,但代价是Rebalance的时间被延长
Group Coordinator是什么?