消息队列
消息队列的基本形态,就是有N个生产者,N个消费者
生产者和消费者解耦了
应用场景
消息队列解耦
一个模块A接收到请求后需要调用模块B,接着等待模块B完成后续工作,才进行回包。这种情况下模块A极度依赖于模块B的运行状况,耦合度较高。如果业务允许的话,模块A完全可以将调用模块B的请求信息丢进消息中转站中,模块B一旦发现中转站中有消息就进行工作。这个中转站就是消息队列,起着解耦合作用
解耦的本质就是A不用关心B的事情,以及不受B执行结果的影响
消息队列削峰
在请求处理链中,各模块的处理能力通常存在较大差异。根据木桶原理,系统的 QPS(每秒查询量)往往受最弱处理模块的限制,这导致上游模块的剩余处理能力无法充分利用,进而造成性能与资源的浪费。为提升系统整体的 QPS,并最大限度发挥上游模块的高响应性能,上游可以将处理完成的消息暂存至消息队列。下游模块则从消息队列中逐步获取消息进行处理,通过延迟处理的方式,实现削峰填谷的效果,有效缓解负载不均问题。
实际场景:1、秒杀场景 2、凌晨录入数据
cnt=1
while [ $cnt -le 10 ]
do
curl -w "\n cost %{time_total}s" -H "Trace-ID:lyydsheep1" -H "Content-Type: application/json; charset=utf-8" -H "User-ID: 7" http://localhost:8080/demo/peak_clipping -d '{"num":1}'
cnt=$((cnt + 1))
done消息队列分发
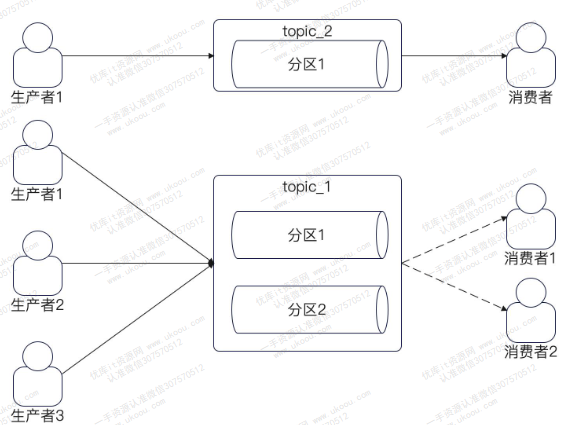
一个模块A需要将消息分发至模块B、C、D
实际场景:1、数据更新 2、数据分析/校验
在引入消息队列之前,生产者需要了解有多少个消费者,以及消费者对于消息的格式化要求。在引入消息队列后,生产者只需要和消息队列打交道,不必关心消费者,也可以说是实现了消息群发场景下的解耦
基本概念
- 生产者 producer
- 消费者 consumer
- 消息服务器 broker
- topic与partition
- 消费者组与消费者
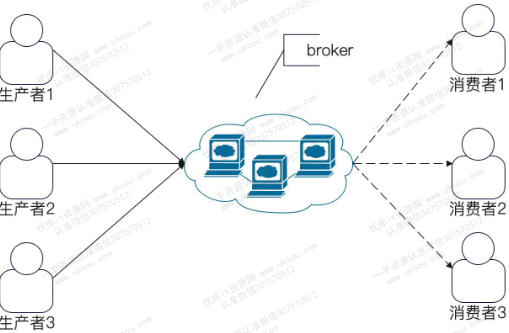
broker(中间人),是一个逻辑上的概念。在实践中,可以映射为一个消息队列进程或一台机器
topic是消息队列上代表不同业务的东西,简单来说,一个业务就是一个topic,而一个topic可以有多个分区
当发送消息到Kafka上的时候,Kafka会先把消息写入主分区,再同步到从分区。这是为了保证高可用和数据不丢失
但通常说topic有多少个分区,是指有多少个主分区
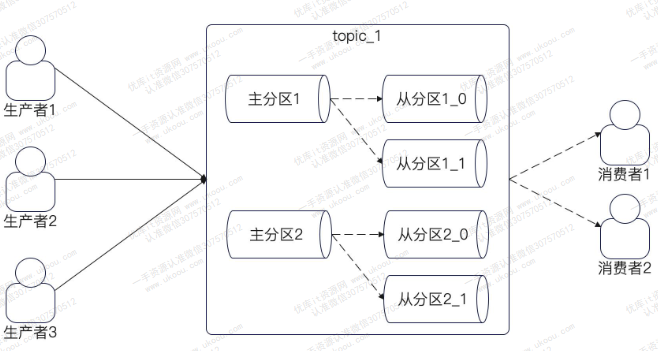
正常情况下,同一个topic的分区会尽量均匀分散到所有的broker上。为了保证当某个broker奔溃后,不会造成很大的影响,需要满足下面两个条件:
- 所有主分区不在同一个broker上
- 同一个topic的分区不都在一个broker上
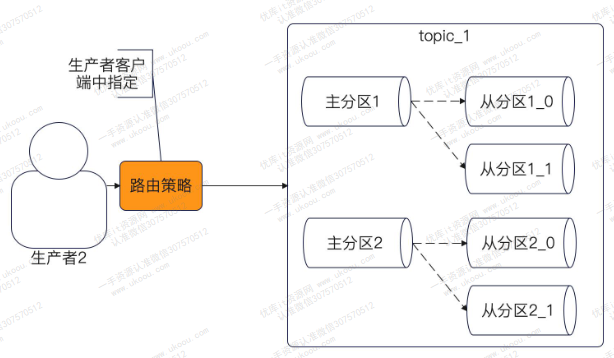
如上文所述,一个topic都会有多个分区,所以发送者在发送消息的时候,就需要选择一个目标(主)分区
比较常用的策略:
- 轮询
- 哈希
- 随机
Kafka消息隔离单位是区,只有一个分区内的消息才能保证是有序的
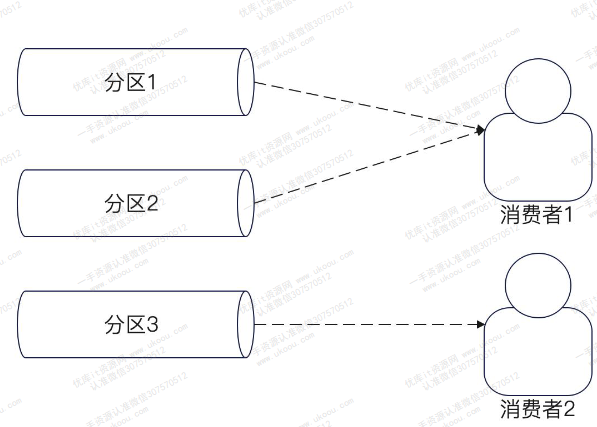
一个消费者组可以看作是关心这个topic的业务方,对于一个分区,同一个消费者组只能有一个消费者出来消费
- 一个消费者可以消费多个分区的数据
- 一个分区在同一时刻,只能被一个消费者消费
消息积压问题
- 如果一个topic有N个分组,那么同一个消费者组最多有N个消费者,多余的消费者会被忽略
- 如果消费者性能低,那么不能通过无限增加消费者数量的方式提高消费速率
命令行工具
sarama提供了许多命令行工具,其中consumer和producer用得比较多
go install github.com/IBM/sarama/tools/kafka-console-consumer
go install github.com/IBM/sarama/tools/kafka-console-producer这些具体工具的使用方法可以参考sarama中的ReadMe文档
Sarama使用
同步发送消息
func TestSyncProducer(t *testing.T) {
cfg := sarama.NewConfig()
// 同步生产者必须设置
cfg.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"localhost:9094"}, cfg)
require.NoError(t, err)
producer, err := sarama.NewSyncProducerFromClient(client)
require.NoError(t, err)
err = producer.SendMessages([]*sarama.ProducerMessage{
{
Topic: "test_topic",
Value: sarama.StringEncoder("message A"),
},
{
Topic: "test_topic",
Value: sarama.StringEncoder("message B"),
},
})
require.NoError(t, err)
}
指定分区
由上文可知,Kafka只能保证一个分区内的消息是有序的。倘若我们希望同一个业务的消息一定发送到同一个分区上,保证业务内消息有序性,可以对sarama.Config.Producer结构体中的Partitioner字段进行配置,如下图:
常见的:
- Random:随机一个
- RoundRobin:轮询
- Hash:根据Message中的key的哈希值来筛选一个
- Manual:根据Message中的partition字段来选择
- ConsistentCRC:一致性哈希,用的是CRC16算法
- Custom:自定义一部分Hash参数
异步发送消息
func TestAsyncProducer(t *testing.T) {
cfg := sarama.NewConfig()
cfg.Producer.Return.Successes = true
cfg.Producer.Return.Errors = true
client, err := sarama.NewClient([]string{"localhost:9094"}, cfg)
require.NoError(t, err)
producer, err := sarama.NewAsyncProducerFromClient(client)
require.NoError(t, err)
msgInput := producer.Input()
msgInput <- &sarama.ProducerMessage{
Topic: "test_topic",
Value: sarama.StringEncoder("message Hello"),
}
suCh, erCh := producer.Successes(), producer.Errors()
// 实践中一般都是开一个goroutine来处理
select {
case msg := <-suCh:
val, _ := msg.Value.Encode()
fmt.Println(msg.Topic, string(val))
case err := <-erCh:
fmt.Println(err.Error())
}
}- 需要把
Success和Errors都设置为true,这是为了后面能异步获取到结果 - 通过一个channel异步发送消息
- 通过
select case,监听异步发送消息的结果
指定acks
生产者在发送数据的时候,有一个关键参数——acks,该参数有三个取值:

- 0:客户端发一次,仅收到TCP的ACK报文(没实质作用)
- 1:客户端发送一次,需要等待服务端将消息写入主分区,能确保消息成功送达
- -1:客户端发送一次,需要等待服务端将消息同步至所有(可配置)的ISR上
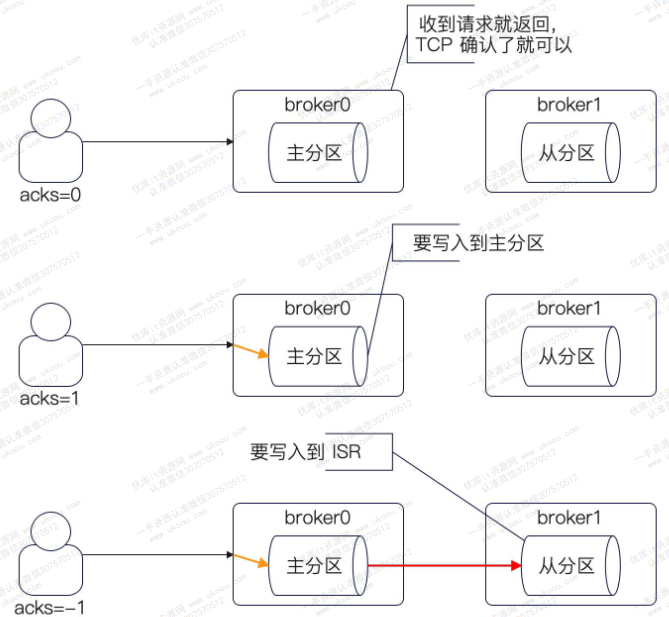
自上而下,性能逐渐变差,但是数据可靠性上升
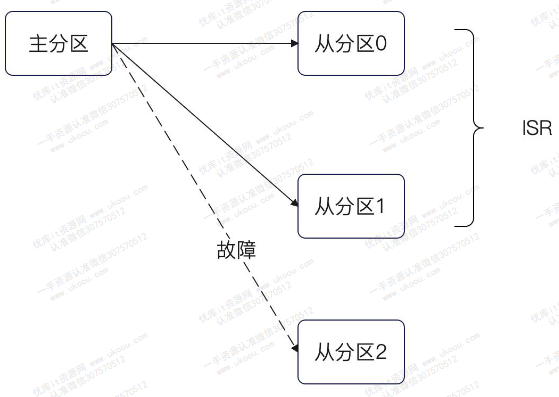
ISR
ISR(In Sync Replicas),就是和主分区保持数据同步的从分区集合
启动消费者
func TestConsumer(t *testing.T) {
cfg := sarama.NewConfig()
// 设置初始消费偏移量,如果没有已提交的offset数据,则默认是下一个消息的位置
//cfg.Consumer.Offsets.Initial = sarama.OffsetOldest
cg, err := sarama.NewConsumerGroup([]string{"localhost:9094"}, "test_id", cfg)
require.NoError(t, err)
// 定时结束
ctx, cancel := context.WithTimeout(context.Background(), time.Second*10)
defer cancel()
err = cg.Consume(ctx, []string{"test_topic"}, &ConsumerHandler{})
}
type ConsumerHandler struct {
}
func (c ConsumerHandler) Setup(session sarama.ConsumerGroupSession) error {
fmt.Println("this is setup")
// 重置偏移量
//partitions := session.Claims()["test_topic"]
//for _, v := range partitions {
// session.ResetOffset("test_topic", v, sarama.OffsetOldest, "")
//}
return nil
}
func (c ConsumerHandler) Cleanup(session sarama.ConsumerGroupSession) error {
fmt.Println("this is cleanup")
return nil
}
func (c ConsumerHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
// 关键实现
msgCh := claim.Messages()
for msg := range msgCh {
fmt.Println(string(msg.Value))
// 标记消费成功,用于移动offset
// 服务端只会提交带有标记的消息,代表该消息被成功消费
session.MarkMessage(msg, "")
}
return nil
}- 初始化一个消费者组
- 调用消费者组的Consume方法
- 为Consume方法传入一个ConsumerGroupHandler接口
- 向Consume方法中传入一个带有定时器或Cancel的Context,可以控制消费者退出
ConsumerGroupHandler接口需要实现三个方法:
- Setup
- Cleanup
- ConsumeClaim
其中消费组对消息进行消费的逻辑在ConsumClaim方法中实现:
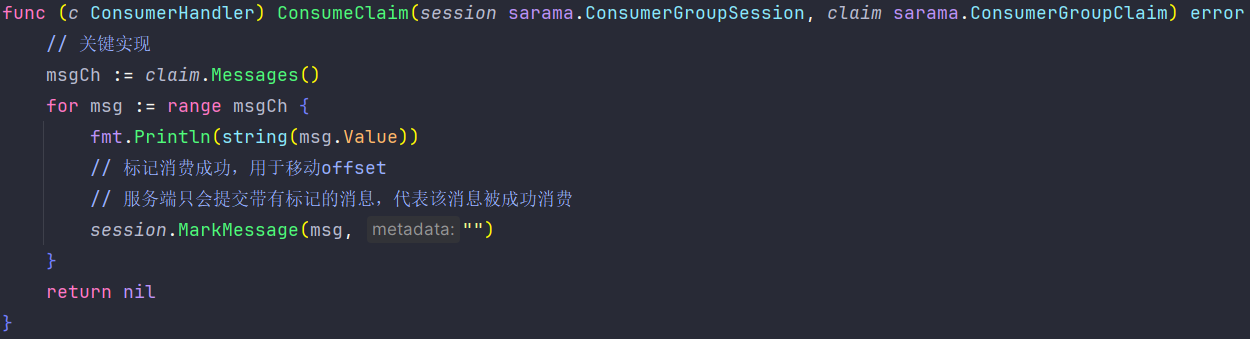
由于Consume方法需要的是一个接口,那么我们可以基于类型定义、结构体等方式花式实现ConsumeClaim方法,以达到一些巧妙的作用
自定偏移量消费
sarama中提供了两个设置偏移量的方法:
设置
cfg.Consumer.Offsets.Initial字段cfg := sarama.NewConfig() // 设置初始消费偏移量,如果没有已提交的offset数据,则默认是下一个消息的位置 cfg.Consumer.Offsets.Initial = sarama.OffsetOldest- 调用`session.ResetOffset()`方法 - ```go // 重置偏移量 partitions := session.Claims()["test_topic"] for _, v := range partitions { session.ResetOffset("test_topic", v, sarama.OffsetOldest, "") }
ResetOffset方法通常在Setup函数中调用
值得注意的是,只有上述两个方式同时执行,消费者组才会从历史第一条消息进行消费。最好的方式是走离线渠道,操作kafka集群去重置对应的偏移量。
异步消费,批量提交
func (h *Handler[T]) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
msgCh := claim.Messages()
for {
ctx, cancel := context.WithTimeout(context.Background(), time.Second*2)
done := false
msgs := make([]*sarama.ConsumerMessage, 0, 10)
evts := make([]T, 0, 10)
for i := 0; i < h.batch && !done; i++ {
select {
case msg, ok := <-msgCh:
if !ok {
// msgCh被关闭
cancel()
return nil
}
var t T
err := json.Unmarshal(msg.Value, &t)
if err != nil {
h.l.Error("fail to unmarshal")
continue
}
msgs = append(msgs, msg)
evts = append(evts, t)
case <-ctx.Done():
done = true
}
}
cancel()
err := h.fn(msgs, evts)
if err != nil {
return err
}
for i := range msgs {
session.MarkMessage(msgs[i], "")
}
}
}
异步消费一批,提交一批。
其中提交一批在实现过程中只需要将最后一个消息标记即可
在select case中有两个分支,一个分支是ctx.Done,可以防止因长时间凑不齐一个batch的消息,而导致的阻塞现象;另一个分支调用errgroup.Go()方法异步处理kafka中的消息
改造统计阅读计数
DDD中的一个重要概念:领域事件
当我们在发送消息时,需要发送的是一个事件,即某个用户阅读了某篇文章的事件。项目结构:
封装批量消费
前文提及cg.consumer()方法第三个参数是一个ConsumeGroupHandler接口参数,我们可以封装一个Handler结构体实现这个接口,这个结构体初始化时接受业务方的消费函数,并在ConsumeClaim()方法中调用下游的消费函数对消息进行处理。具体(批量消费)封装下:
type Handler[T any] struct {
l *zap.Logger
fn func(msgs []*sarama.ConsumerMessage, evts []T) error
batch int
}
func (h *Handler[T]) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
msgCh := claim.Messages()
for {
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
msgs := make([]*sarama.ConsumerMessage, 0, h.batch)
evts := make([]T, 0, h.batch)
done := false
for i := 0; i < h.batch && !done; i++ {
select {
case msg, ok := <-msgCh:
if !ok {
// channel关闭
cancel()
return nil
}
var t T
err := json.Unmarshal(msg.Value, &t)
if err != nil {
// 记录日志
continue
}
msgs = append(msgs, msg)
evts = append(evts, t)
case <-ctx.Done():
// 超时
done = true
}
}
cancel()
err := h.fn(msgs, evts)
if err != nil {
// 记录日志
// 记录整个批次
// 继续消费
}
// 标记消息
for i := range msgs {
session.MarkMessage(msgs[i], "")
}
}
}上述代码实现了对消费者批量消费的封装,可以提高系统处理消息的性能。这是因为批量处理可以将DAO层面10次(假定batch为10)事务处理缩减至在一次事务中处理十次操作。两个注意点:
- 注意超时
- 调用下游
组装消费者
在依赖注入的过程中,消费者类似于Web、GRpc服务器的东西,需要启动。因此引入一个App结构体,对Web和消费者进行组合
// app.go
type App struct {
Web *gin.Engine
Consumers []events.Consumer
}
// ioc/kafka.go
// 由于Go没有动态类型,因此每一个消费者都需要进行注册操作
func NewConsumers(c1 *articles.InteractiveReadEventConsumer) []events.Consumer {
return []events.Consumer{c1}
}
// wire.go
// 组合结构体所有的字段,*表示所有
wire.Struct(new(App), "*")批量生产
svc通过channel将消息发送给生产者,当生产者积累足够多的消息后,就将这一批消息发送给Kafka
func NewBasicInteractService(repo repository.InteractRepository, producer events.Producer) *BasicInteractService {
ch := make(chan events.ReadEvent, 10)
// 凑足一批消息
go func() {
for {
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
evts := make([]events.ReadEvent, 0, 10)
done := false
for i := 0; i < 10 && !done; i++ {
select {
case evt, ok := <-ch:
if !ok {
cancel()
break
}
evts = append(evts, evt)
case <-ctx.Done():
done = true
}
}
cancel()
err := producer.ProduceReadEventV1(ctx, evts)
if err != nil {
// 日志
}
}
}()
return &BasicInteractService{repo: repo, producer: producer, ch: ch}
}
// 积累消息
func (svc *BasicInteractService) IncReadCnt(ctx context.Context, biz string, bizId, uid int64) error {
_, err := svc.Get(ctx, biz, bizId, uid)
go func() {
if err == nil {
svc.ch <- events.ReadEvent{
Uid: uid,
Aid: bizId,
}
}
}()
return err
}