榜单模型与分布式任务调度
实现榜单功能主要有三个要点:
- 如何计算热点
- 如何保证性能
- 如何保证高可用
一个榜单模型需要满足较强的实时性计算,允许在一定时间步长内的数据误差。丐版的实现思路就是定时查询 + 查询数据库 + 排序选出前N个记录
使用time.ticker可以简便地实现定时查询子功能
但是全局扫描数据库和文件排序是比较耗时的步骤,特别是当数据库中具有海量数据的时候,查询数据库的压力会特别大。
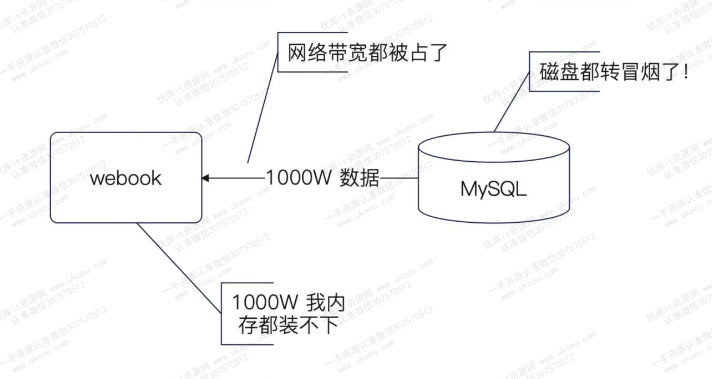
一个解决思路是异步分批查询,将大批量的数据分而治之
计算热点
计算热点不是我们重点考虑的东西,一般都是产品经理提供计算算法,开发人员适当提出建议即可,不必过于纠结于此。计算热点算法一般会包含用户行为、时间、权重因子等部分,例如Hacknews算法、Reddit算法
定时任务
性能和可用性 缺一不可
针对Zset的优化手段
time.Timer
time.Ticker
go.work go work init
//go:generate mockgen
引入一个job模块
适配器模式或者builder模式 —-> 适配corn.Job接口
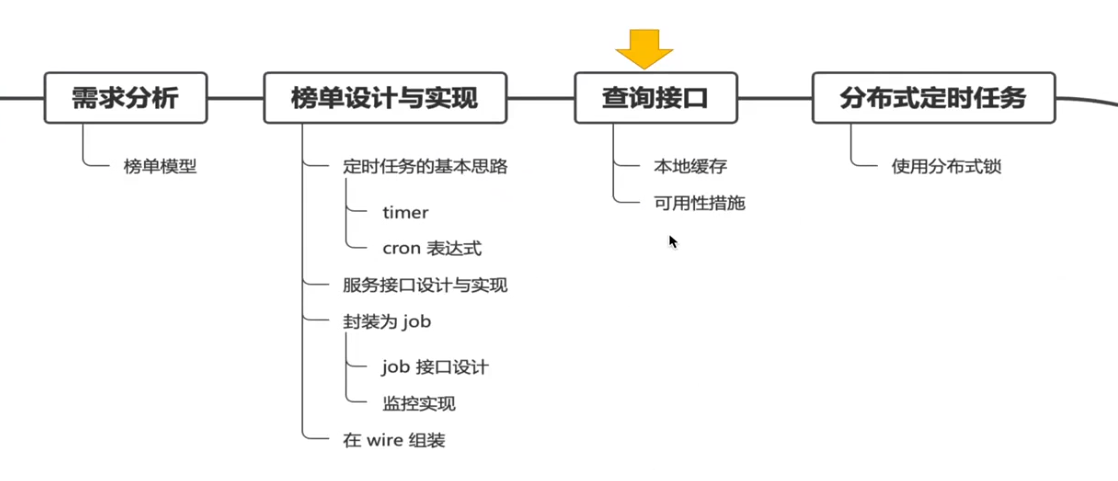
查询接口 —-> 一个高并发且高可用的接口
极致性能 —> 必须要用本地缓存
分布式定时任务:Redis分布式锁
心跳机制