阅读、点赞、收藏
需求分析
- 阅读数量在点击文章之后就会+1,在退出文章后也不会-1
- 点赞和收藏数既可以+1,也可以-1
- 有时收藏的内容会放在收藏夹,取消收藏则要移除收藏夹
另一方面,对于一个平台,不论是文章、视频还是评论,这些对象都会有阅读、点赞、收藏等属性字段。这也就意味着,我们提供的接口不能只限制应用于文章,而是一个面向任何资源都能使用的阅读、点赞、收藏功能接口
更进一步地,需要分析阅读、点赞、收藏这三者之间的界限。实际可以考虑一下三个方面:
- 场景
- 性能
- 研发
阅读数功能设计与实现
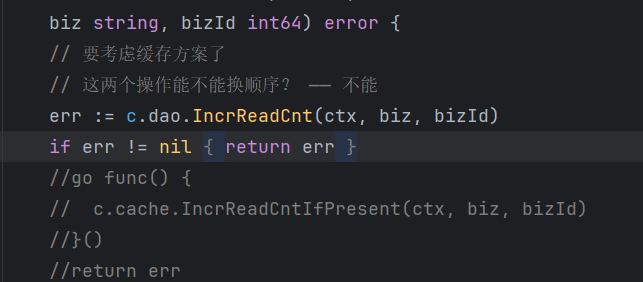
设计一个InteractService接口,该接口提供一个IncReadCnt方法,每当调用阅读接口时,就是该方法将对象的阅读数字段+1。
考虑极端情况,如果是第一次对某个对象调用IncReadCnt方法,那么此时数据库中是没有该记录的,需要进行insert操作,而第二次、第三次调用时则是进行update操作。由此可见,IncReadCnt方法应该实现upsert操作:有记录则更新read_cnt字段,没有记录则插入一条记录
复习一下GORM实现upsert操作:
dao.db.WithContext(ctx).Clauses(clause.OnConflict{
DoUpdates: clause.Assignments(map[string]any{
// 直接使用 `read_cnt` = `read_cnt` + 1
// 保持并发安全
"read_cnt": gorm.Expr("read_cnt + 1"),
"utime": time.Now().UnixMilli(),
}).Create(&Interactive{
// 略
...
})
})在需求分析阶段,我们得出结论:应该提供一个面向任何资源的阅读、点赞、收藏功能接口。既然如此,就得有区分不同资源的字段。一种很常见的方法就是采用biz + bizId来唯一标识某个特定业务下的一个对象
类似的设计有:
- biz + bizId
- resource type + resourceId
- request type + requestId
缓存设计
在任何一个平台,阅读量、点赞、收藏都是高频访问数据。因此需要做好缓存,防止超高的QPS压垮数据库
这里选择使用Redis的Hashes结构,一个key中同时保存read_cnt,like_cnt,collect_cnt字段
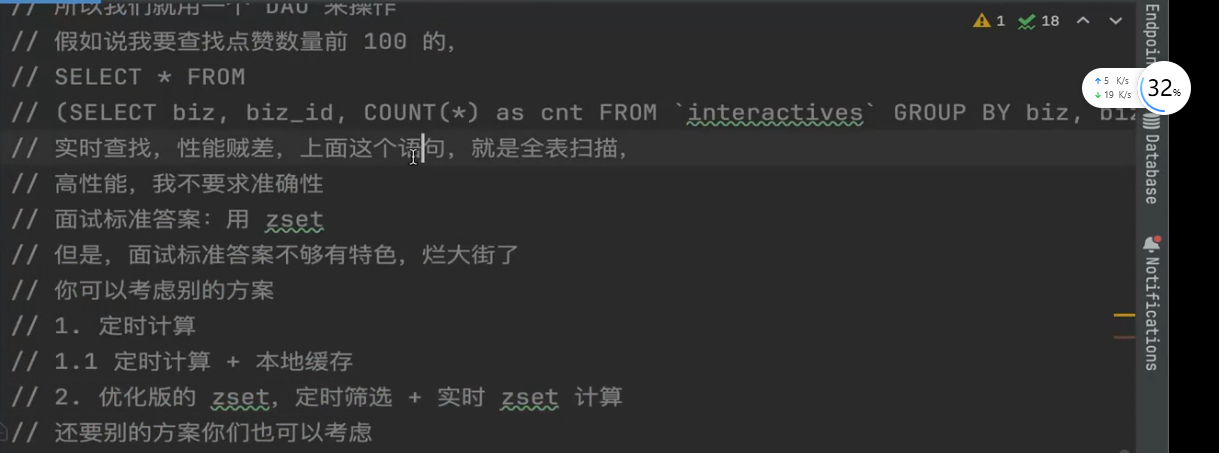
为什么不是三个(广义上)Redis分别保存三个字段的属性值?🤔
一个原因是:阅读、点赞、收藏这三个字段经常一同出现,如果用一个key保存,那么只需要进行一次Redis查询就能拿到三个字段值
另一个原因是:如果使用三个Redis保存,那么为了确保读取三个Redis操作的原子性,就必须使用lua编写复杂脚本(而且性能可能会有一定损失🧐)
枚举使用缓存可能发生的场景:
- 没有Key
- 有Key且有相应的字段
- 有Key但没有相应的字段
幸运地是,Redis提供了一个HCINRBY api(详见下图),可以有效解决后两种情况
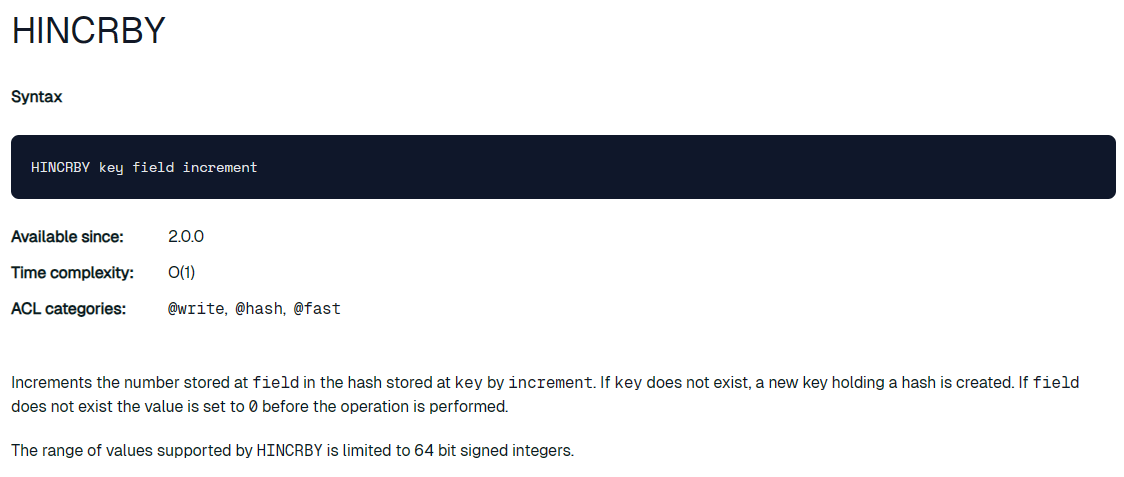
对于情况一:我们就需要事先判断一下Redi中的key是否存在,如果存在就把对应的字段+1。这是一个典型的check-do something场景,可以考虑使用lua脚本确保没有并发问题
注意事项
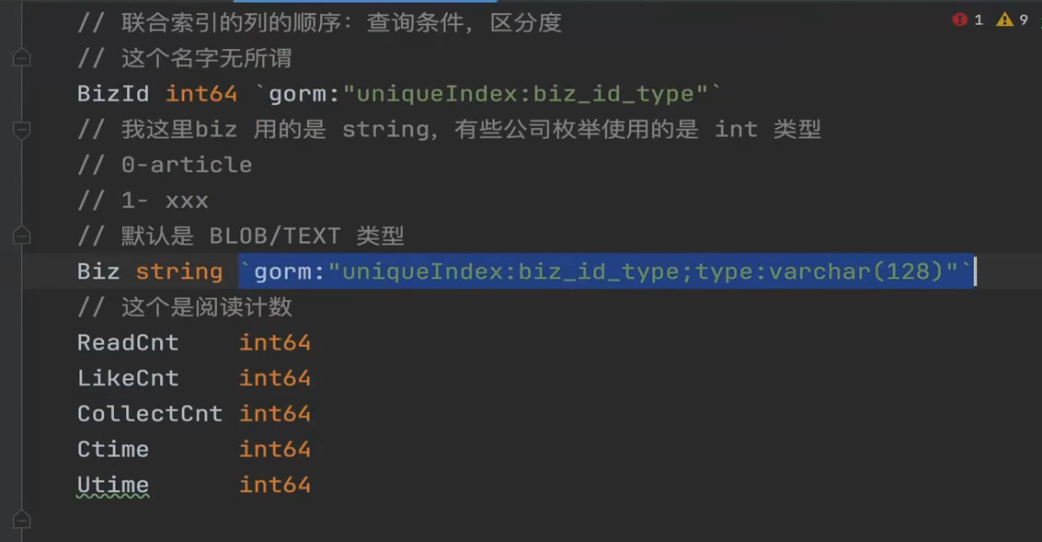
⚠️:存储对象中的string类型默认对应着MySQL中的BLOB/TEXT类型,需要用tag明确指定varchar类型
先更新数据库,再更新缓存
点赞功能设计与实现
需求分析
点赞事实上分成两个部分:
- 保留某个用户是否点赞过,并且用户可以取消点赞
- 统计点赞数量
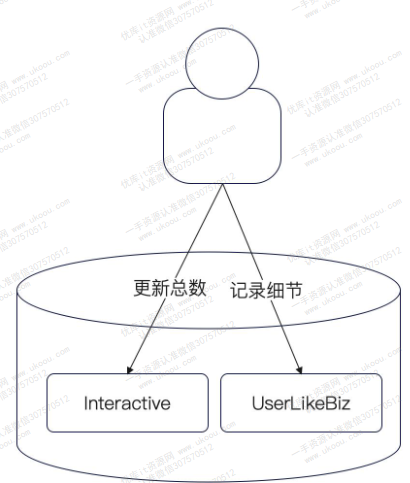
统计点赞数量和统计阅读数量的思路是一样的,不过需要额外记录用户是否对某个资源已经点过赞
功能实现
为了简化前端代码,可以将点赞和取消点赞转发至同一个接口上,通过一个like字段进行区分
true,那么是点赞false,那么是取消点赞
并在Handler中根据like值,调用不同的方法
软删除
涉及到用户可以撤销某个行为的场景(例如本处就是取消点赞),通常有两种操作数据的方式
- 硬删除:直接将数据库中的记录删除
- 软删除:将记录中的
status字段设置成2- 通常为了避免零值问题,人为规定
status = 1标识记录存在,status = 2标识记录被删除
- 通常为了避免零值问题,人为规定
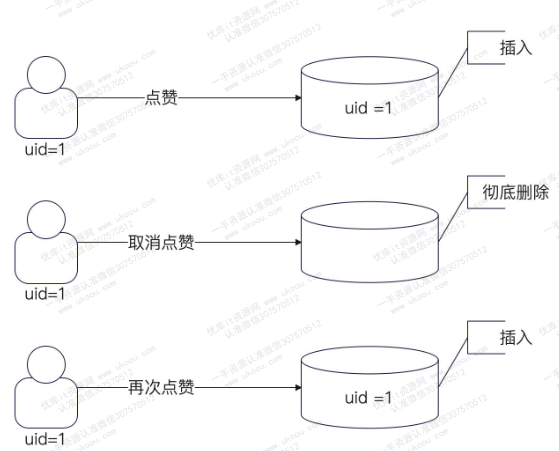
相较于软删除,硬删除会产生很多空洞,影响MySQL性能。换句话说,软删除的性能更好
同样地,在DAO层面,对于点赞操作,不能确定是第一次点赞还会再次点赞。因此需要采用upsert操作
收藏功能设计与实现
这里需要引入收藏夹的概念
总体上就是两张表:
- 收藏夹本体:也就是收藏夹本身,以及其归属的用户
- 收藏夹和资源的关联关系
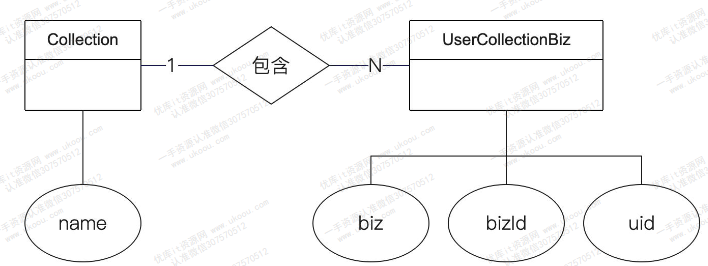
收藏夹中会有多个项目,因此收藏夹和收藏夹中的内容是1:N的关系
具体实现和阅读数、点赞数类似,都是要upsert语义,以及collect_cnt = collect_cnt + 1
查询接口
参考竞品:
在前端做展示一片文章、视频等资源时,需要将资源本体、阅读数、点赞数、收藏数等一同显示
因为在实现阅读、点赞、收藏时,将这些字段视为了一个独立的领域,所以需要提供两个接口分别对数据和资源进行查询,并在Web层面进行聚合。另一种可行的方案就是将数据作为文章的子对象,那么就可以在Service层进行聚合
考虑到需要进行查询多个表的操作,为了提高性能,可以使用errgroup来并发查询数据和资源本体
具体Web层面实现如下:
```
```go
func (h *ArticleHandler) PubDetail(ctx *gin.Context, c jwt.UserClaims, req ArticleReq) (ginx.Result, error) {
uid := c.UserId
var eg errgroup.Group
var art domain.Article
eg.Go(func() error {
var err error
art, err = h.svc.PubDetail(ctx, req.BizId)
if err != nil {
h.l.Error("获取文章失败", zap.Error(err))
}
return err
})
var intr domain.Interact
eg.Go(func() error {
var err error
intr, err = h.interactSvc.Get(ctx, req.Biz, req.BizId, uid)
if err != nil {
h.l.Error("获取文章数据失败", zap.Error(err))
}
return err
})
err := eg.Wait()
if err != nil {
return ginx.Result{}, err
}
go func() {
var err error
err = h.interactSvc.IncReadCnt(ctx, req.Biz, req.BizId)
if err != nil {
h.l.Error("增加阅读数失败", zap.Error(err))
}
}()
return ginx.Result{
Data: ArticleVO{
Id: art.Id,
Title: art.Title,
Content: art.Content,
AuthorName: art.Author.Name,
ReadCnt: intr.ReadCnt,
LikeCnt: intr.LikeCnt,
CollectCnt: intr.CollectCnt,
Liked: intr.Liked,
Collected: intr.Collected,
Ctime: time.UnixMilli(art.Ctime).Format(time.DateTime),
Utime: time.UnixMilli(art.Utime).Format(time.DateTime),
},
}, nil
}
⚠️:
方法不直接修改参数,而是通过返回值间接修改参数
返回值的类型选择:
如果指针实现了接口,那就返回指针
如果返回值很大,避免传递引发复制,那就返回指针
简易原则:
- 接收器永远用指针
- 输入输出都用结构体
不是所有结构体都是可比较的
功能实现小结
- 大量使用事物,保证在操作两张表时保持ACID特性
- 大量使用Upsert语义,因为很多情况下我们不知道表中是否有对应的数据
- 大量使用lua脚本来保证缓存中的数据是正确的,但是无法彻底解决缓存一致性问题
- 在查询接口这个呢,只缓存总数数据,并不会缓存个人是否点赞、是否收藏的数据
- 缓存一致性虽然很重要,但不是所有的场景都必须维护。另一方面,需要彻底解决缓存一致性问题的场景,就不应该使用缓存