Redis对象
String
String就是字符串,是Redis中的一个最基本数据对象,最大存储数据512MB
Set操作
基本语法:**set key value [expiration EX seconds | PX milliseconds] [NX|XX]**
Set操作用于在Redis中设置一个K-V对,其中几个扩展参数作用分别如下:
- EX seconds:设置K-V对的过期时间为多少秒
- PX milliseconds:设置K-V对的过期时间为多少毫秒
- NX:只有当Key不存在时,命令才生效,相当于
setnx key value - XX:只有当Key存在时,命令才生效
⚠️:对一个已经存在Key进行set操作会将原有值覆盖,可能会导致原有值丢失、擦除过期时间、丢失原有值类型
三种编码方式
String对象底层采用三种不同的编码方式以高效应对各种场景
- INT编码:用于存储long范围内的整数
- ⚠️:如果是浮点数,则不能使用INT编码。因为INT编码只能用于表示整数
- EMBSTR编码:如果字符串的大小小于阈值字节,则采用此方式
- RAW编码:如果字符串的大小大于阈值字节,则采用此方式
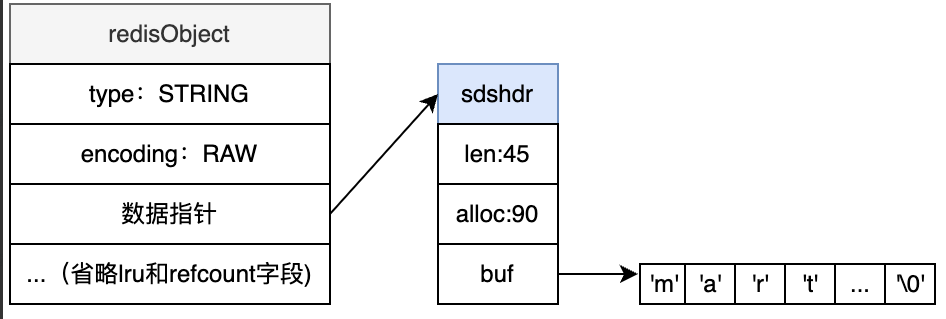
EMBSTR编码和RAW编码方式在底层实现中都是由redisObject和SDS两个结构组成,区别在于这两个结构在物理内存上是否连续(为一整体)
EMBSTR在内存中的表示:

RAW在内存中的表示:
三种编码方式的转换关系
随着对Redis的操作,String对象的编码方式可能有如下变化:
INT –> RAW:当存储的内容不再是整数或大小超过long范围,则需要将INT编码转换为RAW编码
EMBSTR –> RAW:由于EMBSTR编码的String对象是只读的,所以对一个EMBSTR进行写操作时,就会将其编码方式改为RAW。这是因为修改数据就要重新分配存储空间,而EMBSTR中redisObject和SDS是连续的,不易分配空间。并且只要进行修改操作那么就能认为这个String是易变的、不稳定的,采用RAW编码方式能够减少频繁对EMBSTR内存分配的性能损耗
SDS结构
不管是EMBSTR还是RAW,都有一个SDS结构,SDS结构是为了解决C语言中字符串的尴尬处境
- 计算字符串长度需要遍历,时间复杂度$$O(n)$$
- 对字符串追加内容需要扩容操作
- 二进制不安全
- 二进制安全是指公平对待每一个字符,不特殊处理任何字符
- C语言中字符串特殊处理
\0为字符串结尾
SDS结构具体由一下字段组成:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len;
uint8_t alloc;
unsigned char flags;
char buf[];
}- len:表示字符串长度,可以快速返回字符串长度,并且不需要
\0作为结尾符号 - alloc:表示分配了多少内存空间,具有一定的预留空间,无需进行扩容操作
- flags:用于区分具体是什么类型的SDS
- 在Redis中SDS分为sdshdr8、sdshdr16、sdshdr32、sdshdr64
List
3.2版本之前,List对象有两种编码方式
- ZIPLIST
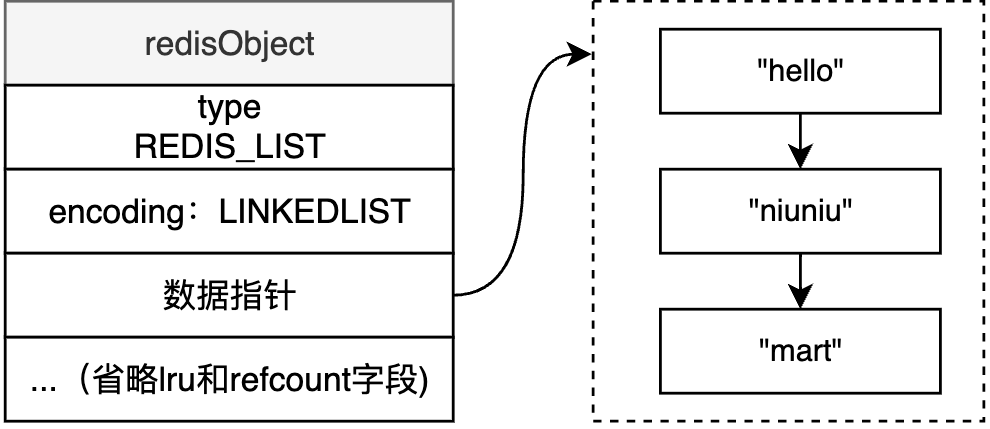
- LINKLIST
当满足以下条件时,采用ZIPLIST编码方式
- 列表对象中所有存储的字符串对象长度都小于64字节
- 列表对象中存储的对象数量不超过512个(这是LIST的限制,而不是ZIPLIST的限制)
🌰:
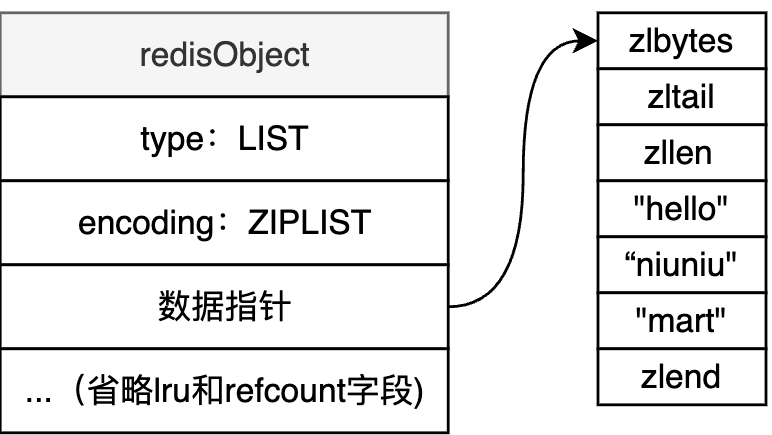
ZIPLIST中数据都是紧密排列的,在数据量小的时候可以有效节约内存;而LINKLIST顾名思义,数据是以链表形式串联起来的,在数据量大的时候采用LINKLIST编码可以加快处理性能
🌰:
QUICKLIST
ZIPLIST在数据较少时节约内存,LINKLIST是为了在数据较多时提高更新效率。但是ZIPLIST在数据稍多时插入数据会导致大量数据复制,占用内存空间;同样地,LINKLIST由于节点数量也异常多,也会占用不少内存
基于上述问题,3.2版本就引入了QUICKLIST。QUICKLIST本质就是ZIPLIST和LINKLIST的结合体
QUICKLIST的实现思路是,将原本LINKLIST的单个节点存储单个数据的模式,更换成一个单个节点(ZIPLIST)存储多个数据的形式
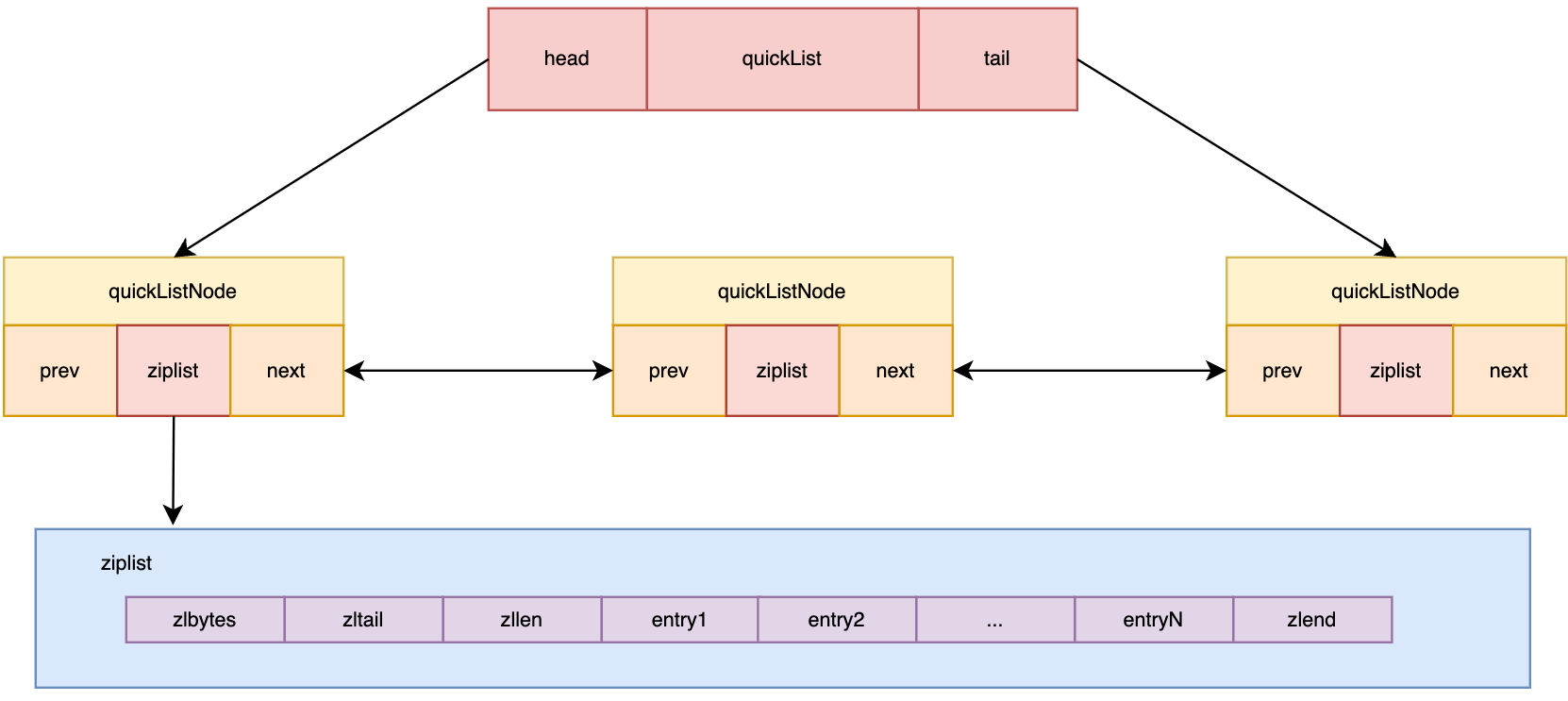
当数据较少时,QUICKLIST节点只有一个,退化成ZIPLIST
当数据较多时,则同时利用了ZIPLIST和LINKLIST的优势
压缩列表
压缩列表作为List的底层数据结构,提供了紧凑型的数据存储方式,能节约内存,小数据量的时候遍历访问性能好(连续+局部性优势)
ZIPLIST整体结构
在Redis代码注释中,有对ZIPLIST清晰地描述:
/* The general layout of the ziplist is as follows:
<zlbytes> <zltail> <zllen> <entry> <entry> <entry> ... <entry> <zlend>
*/🌰:一个具有三个节点的ZIPLIST

zlbytes字段表示该ZIPLIST一共占用了多少字节(包含zlbytes字段的大小)
zltail字段表示最后一个数据节点(entry)距离ZIPLIST首部的偏移字节数,如果ZIPLIST为空(即木有entry),则指示zlend字段的偏移量
很显然,会有如下等式:
zlbytes = zltial + 最后一个entry大小(可能为零) + zlend大小
zllen字段表示ZIPLIST结构中entry的个数,但由于该字段只占用2字节空间,所以最多只能表示65535个。当元素个数过多,只能通过遍历的方式获取元素个数
zlend字段是一个特殊节点,标识ZIPLIST结构的结束
entry字段表示一个数据节点,实际上也是一个结构体类型。该类型由三个字段构成,分别是
<prevlen> <encoding> <entry-data>entry结构
prevlen字段表示上一个数据节点(entry)的长度,如果长度小于254,那么**prevlen字段占用1字节空间;如果长度大于等于254,那么该字段需要用5字节空间表示,并且第一个字节为11111110**,表示这是一个5字节的prevlen信息,剩下的4字节用来表示长度
⚠️:为什么阈值是254而不是255?这是因为255被用来特殊表示zlend字段,标识ZIPLIST结构的结束
encoding字段是一个整形数据,其二进制编码由内容类型和内容数据的字节长度两部分组成
连锁更新
当向一个entry前面插入一个长度超过254的节点时,prevlen字段可能就会由1字节变成5字节,导致本entry长度增大。如果运气不是很好,将会导致下一个节点中的prevlen字段增加,以此类推,造成连锁反应,这就是连锁更新问题。

LISTPACK优化
prevlen字段正是连锁更新的罪魁祸首,为了解决连锁更新问题,就不能再去记录上一个节点的长度,但又要保证能够实现倒序遍历(找到上一个节点的位置)
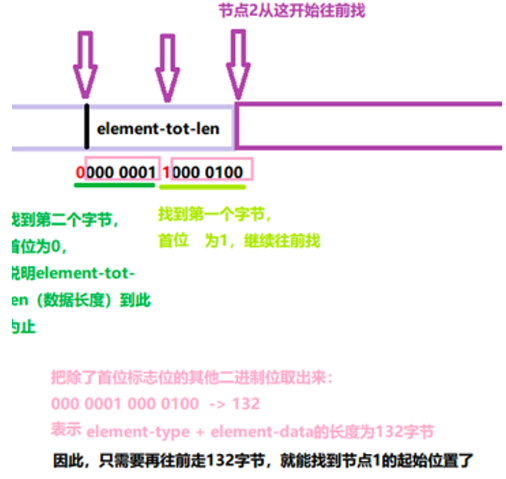
Redis使用了一种巧妙的方法:删除prevlen字段,新增element-tot-len字段记录整个节点除它(element-tot-len字段)自身之外的长度
此时节点结构就变成了:
<encoding-type> <element-data> <element-top-len>- encoding-type是编码类型
- element-data是数据内容
- element-top-len所占的每个字节的第一个bit位用于标识是否结束,0则结束,1则继续
🌰:
Set
Redi中的set是一个不重复、无序的字符串集合
如果Set底层使用INTSET编码方式,则集合是有序的
编码方式
Set底层有两种编码方式:INTSET、HASHTABLE
当Set中存储的都是整数并且元素个数少于512个时,则采用INTSET编码方式
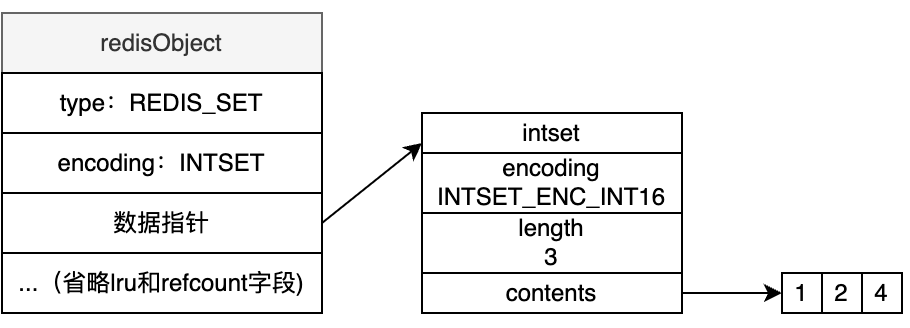
由上图可见,采用INTSET编码,元素排列比较紧凑,内存占用少,但查找时需要使用二分法,时间复杂度为$O(nlogn)$
如果不满足INTSET编码条件,则需要使用HASHTABLE编码,HASHTABLE查询一个元素性能很高,时间复杂度为$O(1)$
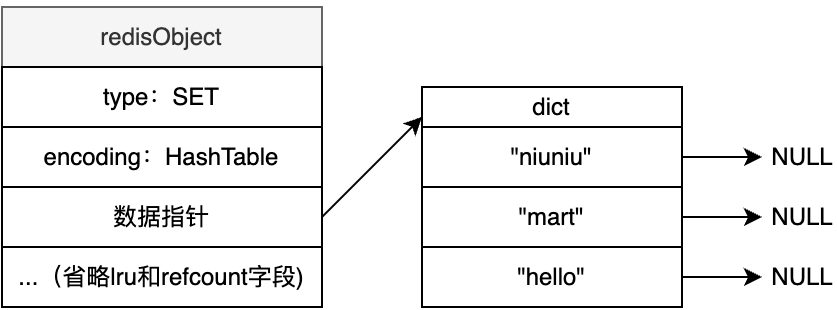
简单地概括:
- INTSET编码适用于存储少量整数场景以节约内存空间
- HASHTABLE编码适用于快速定位某个元素的位置
Hash
// to do
panic(“implement me”)
HashTable
HAHSTABLE是Redis中的一种底层数据结构
通过HASHTABLE可以在$O(1)$时间复杂度内快速定位到Key对于的Value
结构
总所周知,Redis是用C语言实现的。HASHTABLE的C实现涉及到三个结构体:dict、dictht、dicEntry
简单地说,dict封装了两个dictht结构,每一个dictht结构都有一个大小为size的bucket,bucket中存放着dicEntry链表。三个结构体之间的关系如下图所示:
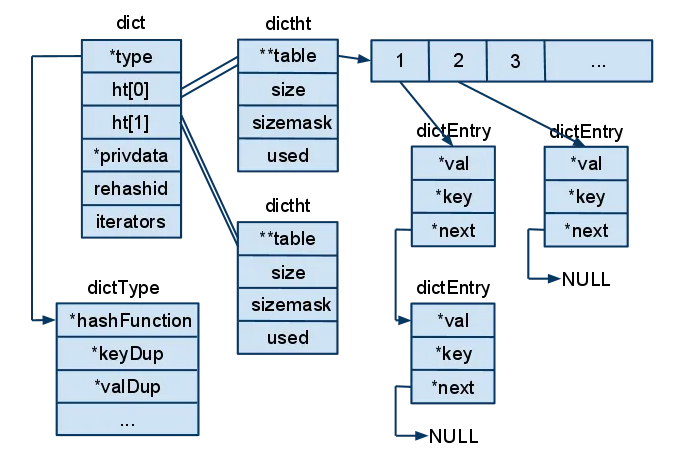
可以看到dict结构中有两个dictht结构,也就是HASHTABLE结构。dicEntry是链表结构,通过拉链法解决Hash冲突
接下来,结合源码j解释每一个结构体的字段含义:
typedef struct dict{
dictType *type; //直线dictType结构,dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据
void *privdata; //私有数据,保存着dictType结构中函数的 参数
dictht ht[2]; //两张哈希表
long rehashidx; //rehash的标记,rehashidx=-1表示没有进行rehash,rehash时每迁移一个桶就对rehashidx加一
int itreators; //正在迭代的迭代器数量
}#dict结构中ht[0]、ht[1]哈希表的数据结构
typedef struct dictht{
dictEntry[] table; //存放一个数组的地址,数组中存放哈希节点dictEntry的地址
unsingned long size; //哈希表table的大小,出始大小为4
unsingned long sizemask; //用于将hash值映射到table位置的索引,大小为(size-1)
unsingned long used; //记录哈希表已有节点(键值对)的数量
}#哈希表节点结构定义
typedef struct dictEntity{
void *key;//键
//值
union{
//“我之所以要提醒你注意这里,其实是为了说明,这种实现方法是一种节省内存的开发小技巧,非常值得学习。因为当值为整数或双精度浮点数时,由于其本身就是 64 位,就可以不用指针指向了,而是可以直接存在键值对的结构体中,这样就避免了再用一个指针,从而节省了内存空间。”
void *val;//自定义类型
uint64_t u64;//无符号整形
int64_t s64;//符合整形
double d;//浮点型
} v;
struct dictEntity *next;//发生哈希冲突时使用。指向下一个哈希表节点,形成链表
}HashTable渐进式扩容
渐进式扩容,顾名思义就是一点一点扩容容量。相比于一次性扩容大量空间,并进行大量的拷贝工作,渐进式扩容不易导致Redis在一段时间内由于进行扩容工作而无法提供其他服务,用户体验感更好。
当dict满足扩容条件后,就会进行Rehash操作。Rehash操作大致分为三步:
为ht[1]哈希表开辟一块空间,空间大小设定为第一个大于2 * ht[0]的2整数次幂。🌰:h[0] = 500,那么在进行Rehash操作时开辟的空间为$2^{\left\lceil log_2(2*500) \right\rceil} = 1024$
迁移ht[0]数据至ht[1]:在Rehash期间,每次对字典进行增删改查操作,程序会顺带迁移当前
rehashidx所指向的数据,并递增下标值。如果当前rehashidx命中了一个空位置,则会先尝试继续往后查找若干位置,如果查询无果就直接返回最终,ht[0]的数据将会全部迁移至ht[1]中。此时,需要交换ht[0]和ht[1]的指针,并将
rehash设为-1,表示处于非Rehash状态- 为什么要交换两张哈希表的指针呢?因为ht[0]代表着正在使用的哈希表
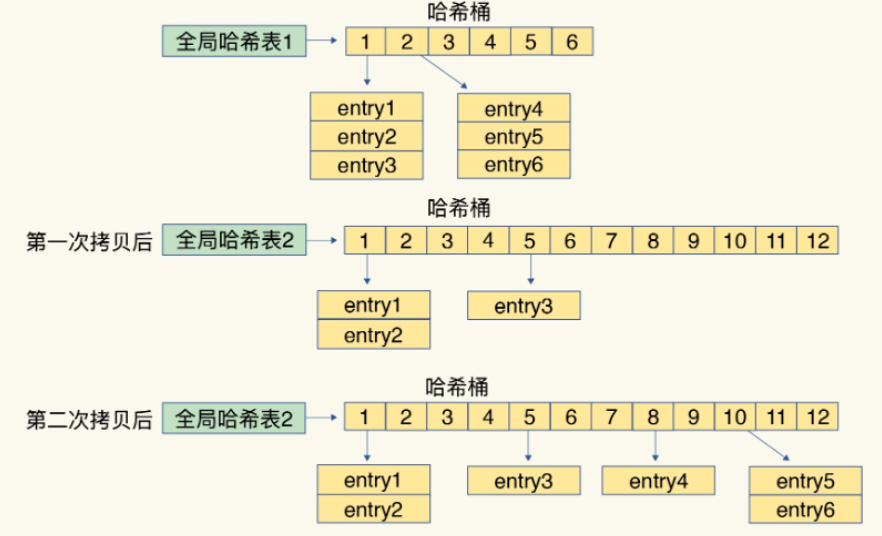
⚠️:值得注意的是,在Rehash阶段,由于存在两张哈希表,此时进行的删除、查找、更新操作会在两个表上进行。比如查找元素时,如果ht[0]表没有找到,则会接着查询ht[1]表。但进行插入操作时,只会在ht[1]表上增添数据
扩(缩)容时机
HASHTABLE由一个变量——负载因子决定是否扩容(缩容)
负载因子的算法:ht[0].used / ht[0].size
扩容场景:
- 负载因子大于等于1并且此时服务器没有执行BGSAVE或BGREWRITEAOF这两个命令
- 负载因子大于5
缩容场景:
- 负载因子小于0.1并且没有BGSAVE或BGWRITEAOF命令在执行
SkipList
跳表的结构
跳表是Redis中ZSET的底层数据结构,跳表本质上就是由链表+多级索引组成的
但Redis使用的跳表并非标准跳表,Redis中的跳表在标准跳表基础之上允许score值重复以及0层节点具有向后指针,如下图所示:
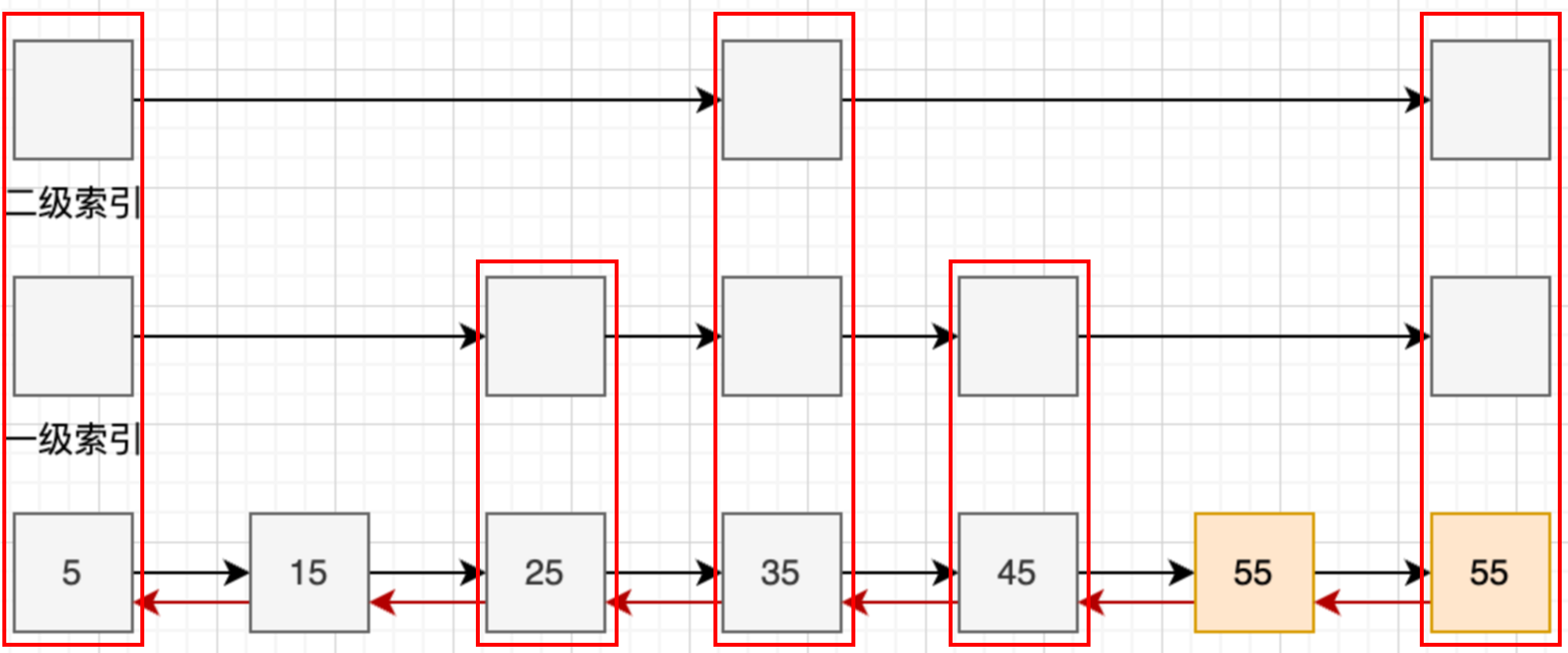
其中红色框中的属于同一个节点的不同层级,跳表中节点的数量体现在0层(最底层)节点的个数
结合源码,分析节点的组成:
// from Redis 7.0.8
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;- ele:sds结构,一个被封装过的字符串,本质上是一个char数组,用于存储数据
- score:双精度浮点数类型,表示该节点的分数,决定了跳表中节点的位置次序
- backward:指向上一个节点的回退指针
- level:是一个zskiplistLeve结构体数组,用于表示高层索引。zskiplistLeve结构体包含了两个字段,一个是forward,指向同层的下一个索引;另一个是span,记录了距离下一个索引(节点)的步长
示意图:
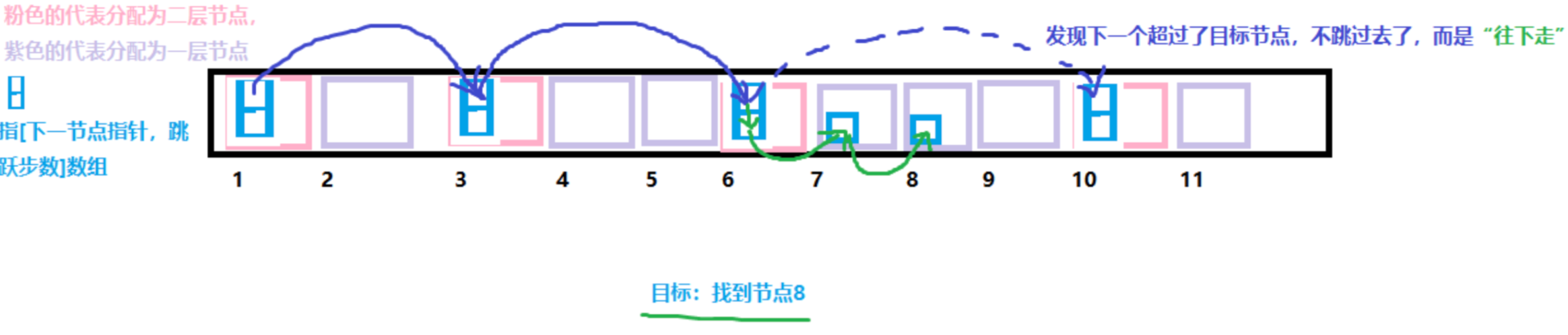
实现细节
Redis跳表中单个节点的层数由概率决定。每插入一个节点到0层,Redis决定该节点是否增加一层索引的概率为25%
跳表将纯粹的有序单链表在插入、删除、更新操作从$O(n)$时间复杂度降低至$O(logN)$
ZSet
Zset也叫Sorted Set即有序集合,是按照元素的分数进行排序的集合。分数相同的情况下,按照元素的字典序进行排序
ZSet常用于排序集合的场景,最典型的就是游戏排行榜
编码方式
ZSet有两种底层编码方式,一种是ZIPLIST,另一种是SKIPLIST+HASHTABLE
如果满足下列条件,ZSet就用ZIPLIST编码方式:
- 列表对象保存的所有字符串长度均小于64字节
- 列表对象保存的元素个数少于128个
ZIPLIST依旧保持着它的优点,在数据量较少时,十分节约内存空间。当ZSet采用ZIPLIST编码时,底层结构如下图:

但凡上述的两个条件有一个不满足,ZSet就采用SKIPLIST+HASHTABLE的编码方式。其中,SKIPLIST是一个具有多级索引的有序链表,可以实现高效的查询、插入、删除操作。除此之外,Redis还利用HASHTABLE结构实现在$O(1)$时间复杂度下查询到ZSet中任一成员的score值