Redis运行原理
Redis在内存中是如何存储的?
简单来说,Redis就是一个运行在内存中的k-v字典。说到k-v字典,很容易联想到Redis底层数据结构dict(HASHTABLE),实际上从C代码中可以看出,Redis数据库就是在dict基础上封装了众多功能(装饰器模式万岁😆)
typedef struct redisDB {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
long long avg_ttl;
list *defrag_later;
} redisDb;核心结构dict值得重点关心:
typedef struct dict{
dictType *type; //直线dictType结构,dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据
void *privdata; //私有数据,保存着dictType结构中函数的 参数
dictht ht[2]; //两张哈希表
long rehashidx; //rehash的标记,rehashidx=-1表示没有进行rehash,rehash时每迁移一个桶就对rehashidx加一
int itreators; //正在迭代的迭代器数量
}当我们使用Redis存储键值对时,dict字段存储这字符串类型的key以及任意类型的value
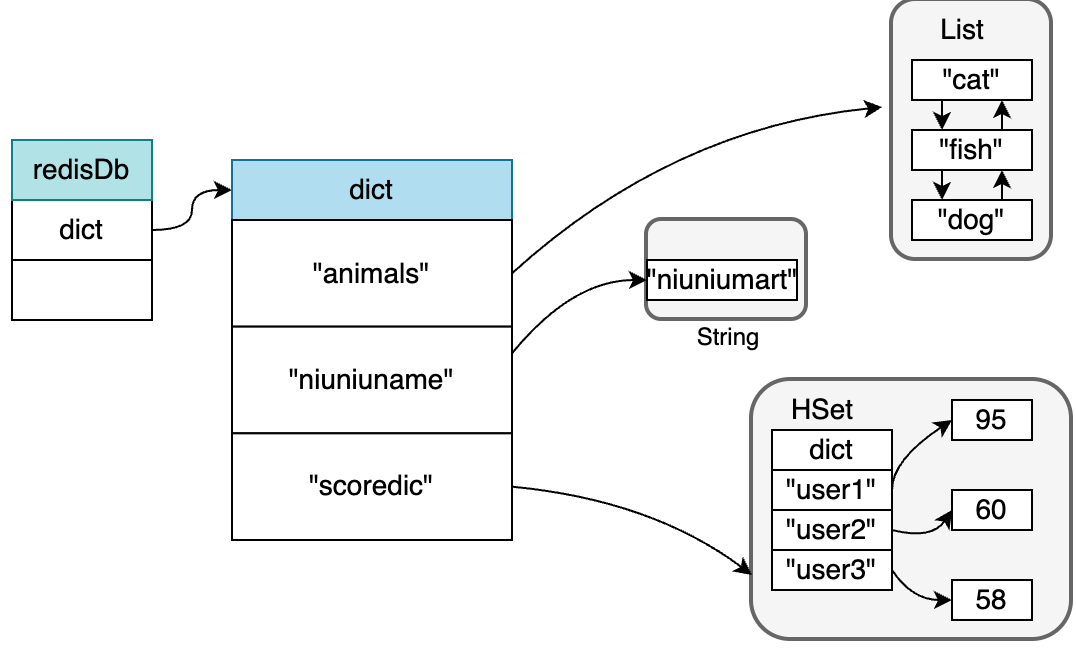
除了dict字段,expire字段也很重要。众所周知,Redis在存储k-v时可以为键值对设置过期时间,提高Redis对内存的使用效率。expire字典中就存储着具有过期时间的键值对信息,其中key就是键值对的键,而value就是对应的过期时间。具体如下图所示:
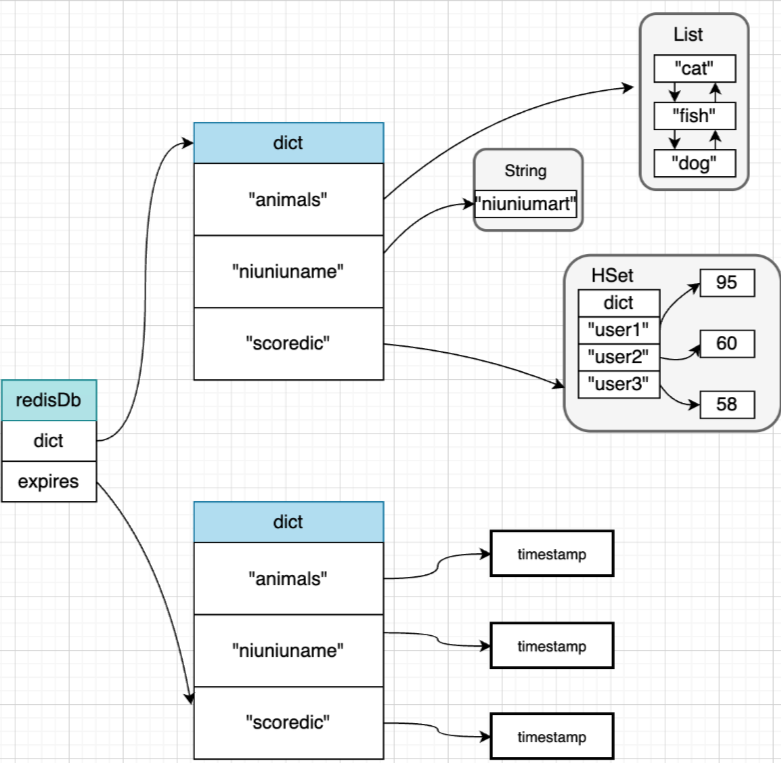
可以看到,在dict和expire其实是具有一些相同的key的,Redis为了节省内存开销,实际上并没有存储了两份一模一样的key,而是进行了内存复用操作。什么意思?简单地说,dict字典和expire字典都指向了同一块内存空间的key。🌰:dict中的animal执行内存0xababababa,expire中的animal也指向内存0xababababa
Redis是单线程还是多线程?
先上结论,Redis作为一个能够高效处理数据请求的组件,主模块使用单线程;辅助模块,例如异步操作、网络I/O则使用多线程
为什么Redis主模块不使用多线程?
如果对底层存储有一定了解的话,那么对下面这张图一定不陌生。(来源)
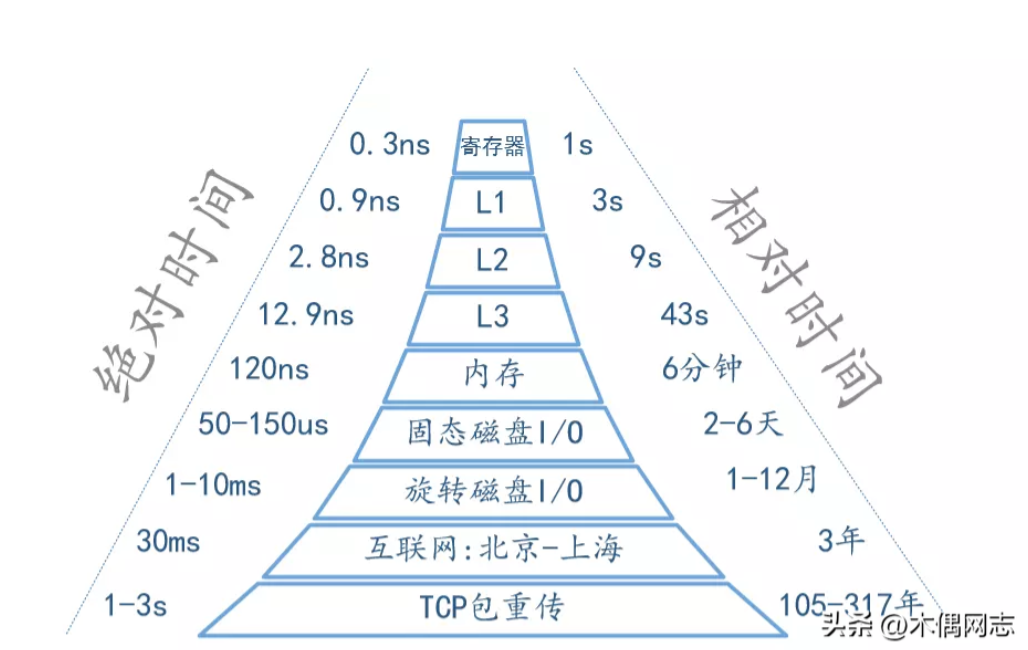
我们知道,多线程可以充分利用CPU多核的运算能力,但是对于主要工作内存上的Redis来说,CPU并不是主要的性能瓶颈。由上图我们也可以很容易猜到Redis性能主要受限于网络IO。
另一方面,Redis的宗旨是“惜内存如金,简单高效”,引入多线程反而导致项目复杂、不易维护,同时也会带来一定的成本开销。具体有以下几个方面:
- 引入多线程后,Redis为了支持事务的ACID就不得不额外添加一些复杂的操作,甚至需要将原有的数据结构改造成并发安全的
- 上下文切换成本:CPU在进行线程调度时需要先保存当前线程的上下文数据,再切换到下一个线程
- 多线程同步机制(加锁、解锁)会引入一定的CPU开销
- 内存消耗:每一个线程都是占用一定的内存资源的,对于Redis来说,内存资源十分宝贵,能省则省
为什么Redis单线程这么快?
我们知道,Redis是单线程处理请求,但是Redis却能做到10w量级的QPS,关键点有以下几个:
- Redis大部分操作都是在内存上完成的,内存操作本身就很快
- Redis中各式各样的数据结构底层依据不同场景采用不同的编码实现方式,使得Redis在各种场景下都能保持高性能(来源)
- Redis采用IO多路复用机制解决网络IO阻塞问题,避免Redis单线程在处理网络请求时频繁发生阻塞,提高了Redis网络吞吐量
下面着重讲讲Redis的网络IO多路复用机制
一般地,如果没有IO多路复用,那么Redis是如何处理请求的?
🌰以一个GET请求为例:
- 客户端发送GET请求,Redis调用accept函数与其建立连接
- Redis调用recv函数从套接字中获取请求
- 解析客户端请求,获取参数
- Redis处理来自客户端的参数,本例中就是获取key所对应的value
- Redis通过send函数将结果返回给客户端
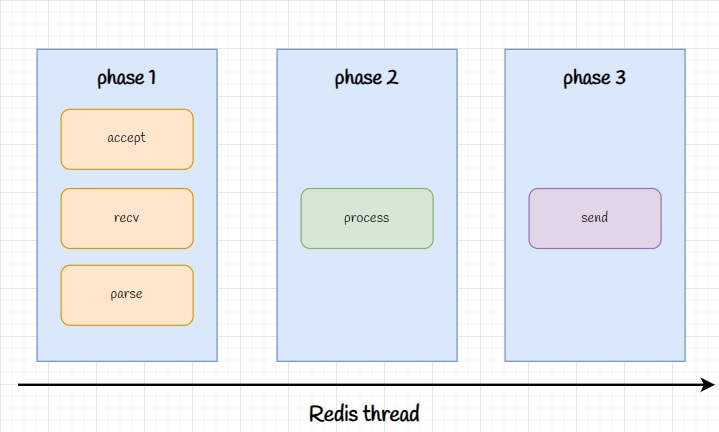
由于套接字采用默认阻塞模式,因此Redis在进行accept和recv时就有可能出现阻塞,比如accept建立链接时间过长、调用recv后,客户端迟迟没有发送数据,这对单线程的Redis来说是致命的。
于是Redis采用IO多路复用机制解决阻塞问题。在Redis中,将套接字设置成非阻塞模式,并且基于系统函数封装了一个reactor模型。简单来说,每当有事件发生,reactor模型就通知不同的处理器去处理事件,这样就不会阻塞在某一个操作上,充分利用了CPU
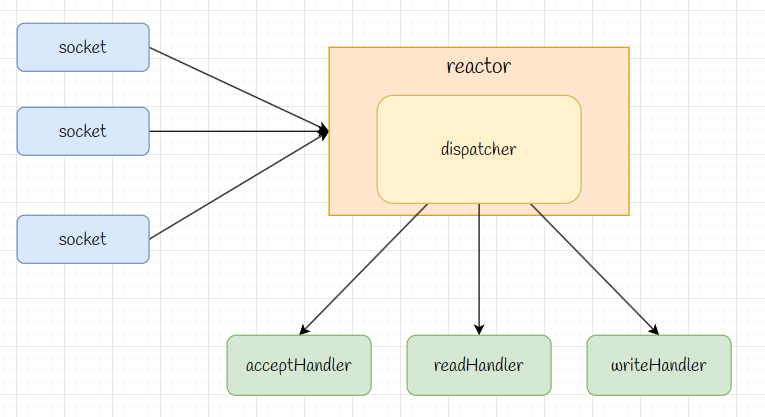
⚠️:这是仍是并发运行,而非并行
内存淘汰策略
我们知道Redis将所有的数据保存在内存上,但是内存空间是有限的,随着时间的推移,有限的内存空间肯定是不能满足无限的数据。因此,Redis需要采用一些内存淘汰策略将“无用”的数据丢弃,以获得更多的空闲内存空间保存数据。
在Redis中有如下几种内存淘汰策略:
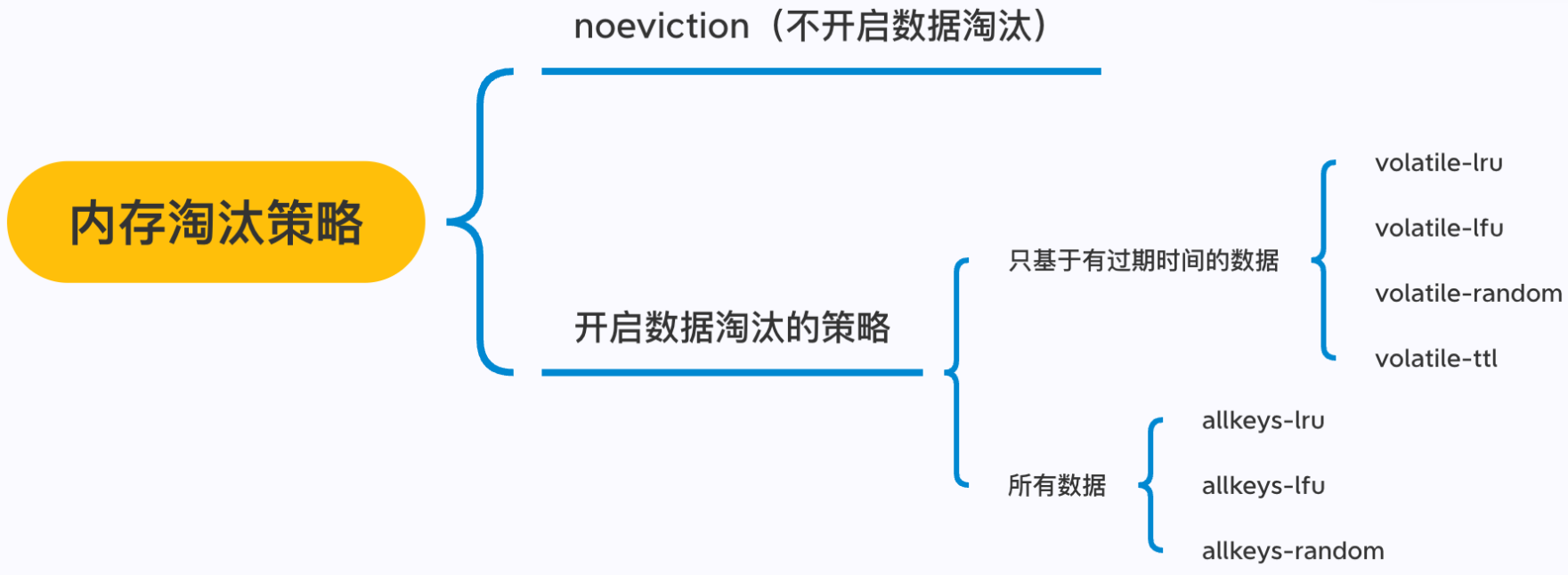
现着重考虑LRU和LFU算法
LRU算法
LRU(Least Recently Used)算法的一般实现就是维护一个按时间戳有序的(双向)链表,每次将链表末尾的节点淘汰,即删除最久未被访问的元素。
Redis采用的是一种近似LRU算法,因为使用正统的LRU算法就意味着需要维护一个包含全局元素的链表,这对于Redis来说成本是巨大的,所以Redis选择一种近似的LRU算法作为内存淘汰策略。
Redis使用的近似LRU算法会维护一个大小为16的淘汰池,下面根据淘汰池是否有空余位置进行分类讨论:
- 当淘汰池未满时,每次从全局随机选取5个元素,放入池子中,然后淘汰池子中空闲时间最大的元素
- 当淘汰池满了,每次从全局随机选取5个元素,但这5个元素只有空闲时间大于池中元素的最小空闲时间的,才会被放入池中。最后将淘汰池中空间时间最大的元素淘汰