《Go语言精进之路》阅读笔记
第10条:使用iota实现枚举常量
Go的const语法提供了“隐式重复前一个非空表达式”的机制
- go
const ( Apple, Banana = 11, 22 Strawberry, Grape Pear, Watermelon ) // 等价于 const ( Apple, Banana = 11, 22 Strawberry, Grape = 11, 22 Pear, Watermelon = 11, 22 )
iota表示const声明块中每个常量所处位置在块中的偏移量
配合隐式重复非空表达式机制,可以实现一些很神奇的效果
- go
const ( a = 1 << iota // 1 b // 2 c // 4 d = iota // 3 e = 1 << iota // 16 ) // 可以效仿标准库中的代码,略过一些iota值 // $GOROOT/src/syscall/net_js.go go 1.12.7 const ( _ = iota IPV6_V6ONLY SOMAXCONN SO_ERROR )
Go引入iota有以下好处:
- iota使得维护枚举常量列表更容易
- 更为灵活的形式为枚举常量赋初值
第12条:使用复合字面值作为处置构造器
- 通过**
filed:value格式的复合字面值进行结构体类型**变量初值构造。未显示指明的结构体字段将采用其对应类型的零值
err = &net.DNSConfigError{err}
替换为
err = &net.DNSConfigError{Error: err}- 通过
index:value格式为数组/切片中非连续的元素赋予初始值
var data = []int{0:-10, 1:-5, 2:0, 3:1, 7:7}- 使用
key:value形式的复合字面值为map类型变量赋初值
m := map[string]int{"k":1, "kk":2}第13条:了解切片实现原理并高效使用
- 切片是数组的“描述符”
//$GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}字段len取决于切片“窗口”(包含元素个数)的大小
字段cap取决于底层数组的大小
使用cap参数创建切片可以提升append的平均操作性能,减少或因动态扩容带来的性能损耗
第14条:了解map实现原理并高效使用
map表示一组无序的键值对,其中value的类型没有限制,但是key的类型必须能够进行**==和!=**操作。因此,函数、map、切片类型不能作为map的key
map不支持“零值可用”,未显示赋值时,map类型的变量的值为nil。对处于零值状态的map变量进行操作会导致运行时panic
和切片一样,map也是引用类型。当函数参数类型是map时,参数传递损耗很小,并且函数内部对map进行的修改是在外部可见的
总是使用“comma ok”惯用法读取map中的元素
遍历map时,Go运行时会随机初始化迭代器的起始位置。因此,多次遍历map得到的键值对次序可能不一致。要想保证遍历键值对的次序固定,可以先用一个切片保存好所有的key,然后再通过遍历切片达到有序遍历map的目的
map的内部实现
runtime.hmap类型是语法层面map类型的运行时对应类型,hmap可以理解为是map类型的描述符,包含了map类型操作所需的所有信息
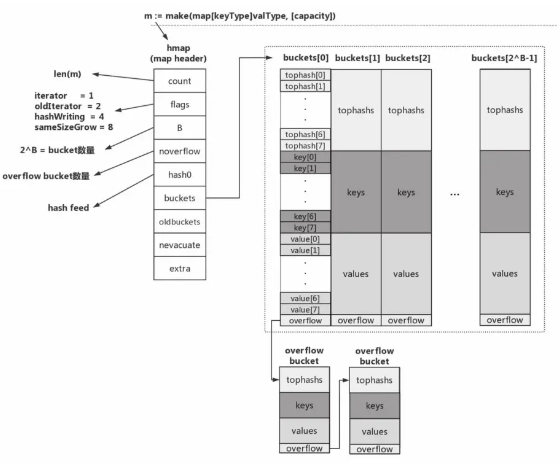
- count:当前map中的元素个数
- flags:当前map所处的状态
- iterator
- oldIterator
- hashWriting
- sameSizeGrow
- noverflow:overflow bucket的大约数量
- hash0:哈希函数种子
- buckets:指向bucket数组的指针
- oldbuckets:在map扩容阶段指向前一个bucket数组的指针
- nevacuate:在map扩容阶段充当扩容进度计数器
- extra:可选字段
Go运行时会将map的key通过哈希函数得出一个哈希值,接着利用哈希值的低位(默认是低8位)找到对应的bucket,然后再拿着哈希值剩下的数值在bucket中的找到目标或空闲槽位(slot)。hashcode中的高位区就存储在bucket中的tophash区域
Go运行时会为map类型生成runtime.maptype实例,这个实例包含了map类型的所有元信息。根据这些元信息,Go运行时可以确定key的类型和大小以及构建value区域
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // 表示hash bucket的内部类型
keysize uint8 // key的大小
elemsize uint8 // elem的大小
bucketsize uint16 //bucket的大小
flags uint32
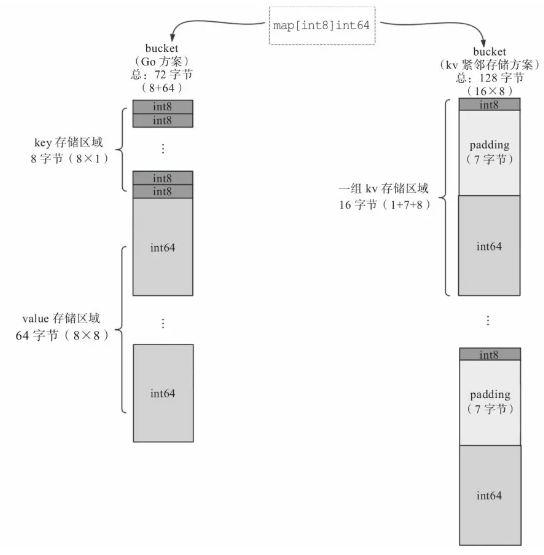
}Go运行时采用了将key和value分开存储而不是选择key和value紧密相接的存储方式。虽然这带来了算法实现上的复杂性,但却减少了内存对齐带来的内存空间损耗
map描述符runtime.hmap自身是有状态的,并且没有对状态进行并发保护,所以map不是并发安全的数据结构。当多个goroutine同时对一个map进行读写操作时,会诱发panic,导致程序崩溃。
考虑到map会自动扩容,bucket地址会不断变化,因此Go不允许获取map中value的地址,并且这个约束是在编译期间就会生效的
第15条:理解string实现原理比高效使用
- string类型的数据是不可变的
- 零值可用
- 获取长度时间复杂度为$$O(1)$$
- 支持通过
+ / +=运算符拼接字符串 - 支持各种比较运算符
- 对非ASCII码原生支持
- 原生支持多行字符串