LLM
简单地理解,就是一个根据输入预测输出的函数。
Function Calling
大模型(LLMs)不擅长逻辑处理,本质上是因为它们是概率机器,而不是符号推理机器。它们的核心能力是模式匹配和预测,而不是遵循严格的逻辑规则进行演绎。
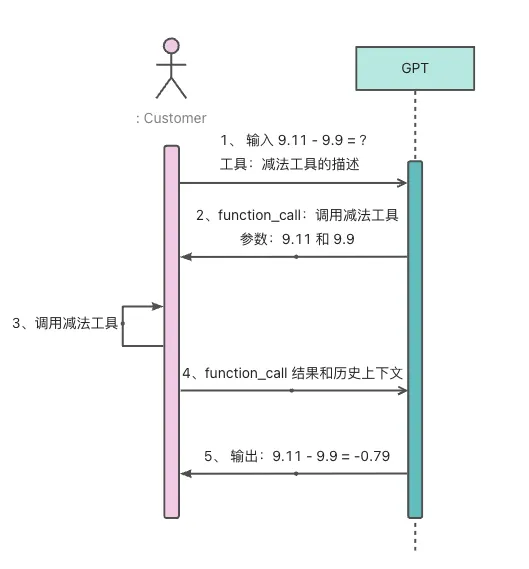
但是类似于计算表达式等逻辑处理过程可以很好地使用代码封装成一个函数,有了现成的函数之后,大模型只需要提供对应的入参即可解决复杂地逻辑处理问题。
通过这种方式将大模型不擅长的逻辑处理问题转化为其最擅长的文本生成问题,能够高效地弥补大模型低逻辑处理能力。
eg:
MCP
为什么要有 MCP?
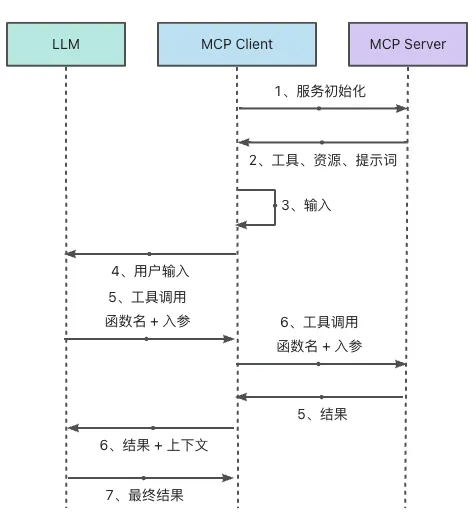
为了解决集成碎片化问题(标准化),这是 MCP 出现最直接的原因。在 MCP 之前,如果想要让一个 LLM 调用工具,由于各个大模型厂商提供的接口/规格不同,那么就必须为每一个平台(ChatGPT、Gemini)定制化功能相同的工具。这会带来极大的时间成本。
没有什么问题是加一层抽象层解决不了的。MCP的做法恰好印证了这一点,MCP 通过引入 MCP 客户端,作为 LLM 和外界沟通的代理。将原先工具接入 LLM 的问题,转化为将工具接入 MCP 客户端,屏蔽了不同 LLM 厂商之间的差异性。
A2A
A2A 协议是基于 Web 标准(HTTP、JSON-RPC、SSE)构建的,核心目的是打造 Agent 和 Agent 之间沟通的桥梁。
一个完整的 Agent 解决方案可能会使用到 MCP 和 A2A 两种协议。比如一个 Agent 通过 MCP访问数据获取最新的数据,然后通过 A2A 协议将
AI 编辑器使用技巧
使用 AI 的场景无非两种场景:(帮助用户)读场景、(帮助用户)写场景
四要素 prompt 框架
角色 (Role): 你是一位精通Go和AI Agent的资深软件架构师。
任务 (Task): 你的任务是分析ReAct Agent的核心实现逻辑,并生成一份技术梳理文档。
背景 (Context): 这份文档将作为内部知识库的核心内容,帮助团队快速上手
约束 (Constraints): 文档必须包含流程梳理、接口文档和Mermaid流程图三个部分。- 角色:这为我们的对话设定了专业的基调和视角
- 任务:明确成功(工作结束)的标准
- 背景:让 AI 理解任务的价值
- 约束:明确输出结果
根据四要素 prompt 框架定义好提示词后,开发者也可以让大模型发起提问,答复大模型提出的问题,不仅能让开发者明确需求的核心要求、抹除歧义,也能很大程度上规避由于开发者表述不清导致大模型无法准确理解需求的问题。
EPCC 协作框架
- Explore:这个阶段的目标是让开发者和大模型建立共享、准确的上下文,即开发者和大模型都需要对项目/目标一清二楚。建立标准化的分层文档体系,确保 AI 在开发环节都有充分的上下文信息
- 分层上下文管理(context)
- 用户全局层、项目维度层、模块维度层、需求维度层
- 标准化文档模板
- PRD、技术方案、测试用例等规范化模板
- 明确输入输出规范
- 每一个环节交付物标准和约数条件
- 版本化约束管理(rules)
- 技术栈、编码规范、质量标准的统一管理
- 分层上下文管理(context)
- Plan:提出一个详细的实现方案,在这一步可以参考多个大模型的方案,最终选择一个最优解,并让大模型根据方案生成一份清晰、步骤化的任务列表。将复杂需求分解为可执行的原子任务。
- 核心流程
- 需求创建
- 任务拆解
- 渐进执行
- 状态跟踪
- 核心流程
- Code:核心原则是小批量、可验证
- TDD(测试驱动开发)
- Commit:让大模型扮演一名“苛刻的评审专家”,对项目的代码、文档进行 review
Prompt Engineering
- Zero-shot Prompting(零样本提示)
- Few-show Learning/Prompting(少样本学习/提示)