Golang深入理解GPM模型学习笔记
协程调度器的核心作用就是将协程关联到内核线程,内核线程无需切换就能执行用户态中的不同功能,提高了并发度
GMP模型
GMP模型设计布局如下图所示:
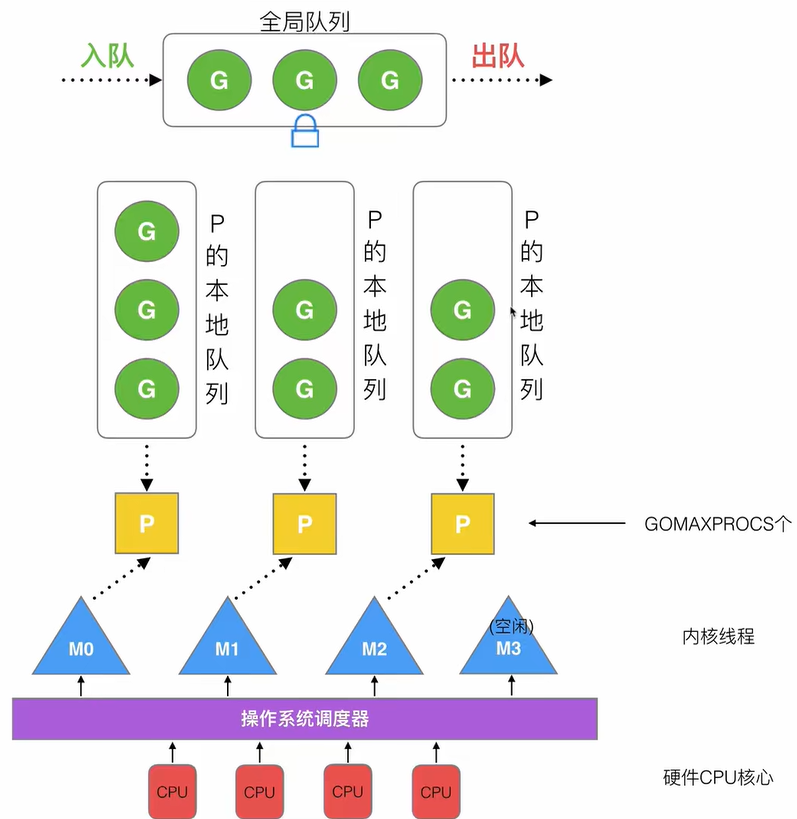
- G:Goroutine,Go协程
- P:Processor,逻辑处理器
- M:Machine,系统级线程
- 全局队列:存放待调度的Goroutine
- 本地队列:存放某一个Processor即将调度的Goroutine
- 一个本地队列中最多容纳256个Goroutine
- 当创建一个Goroutine时,会优先将Goroutine放在本地队列中。如果没有本地队列存在空闲空间,那么新创建的Goroutine就会被放入全局队列
- GOMAXPROCS:配置逻辑处理器个数的参数,决定了Goroutine的并行能力
- 可通过环境变量
$GOMAXPROCS设置 - 或者在程序中通过
runtime.GOMAXPROCS()来设置
- 可通过环境变量
调度器的设计策略
- 复用线程:避免频繁创建、销毁线程带来巨大的开销
- work stealing:当本线程无可调度的Goroutine时,就会“偷取”其他线程待执行的Goroutine来执行
- hand off:当本线程运行的Goroutine发生了阻塞,就会创建/唤醒一个新的线程,新线程接管这个阻塞G的P
- 利用并行:通过
GOMAXPROCS参数调节可同时工作的Processor,即最多有GOMAXPROCS个协程并行工作 - 抢占:coroutine是协作式的,只能由coroutine主动让出CPU资源。而Go调度器为了调度公平,规定每个Goroutine最多占用10msCPU时间,超过这个时间就会被强制下线
- 全局队列:当线程无法从别的线程中“偷取”可调度的Goroutine时,就会从全局队列中获取一个Goroutine进行执行
Go指令的调度流程
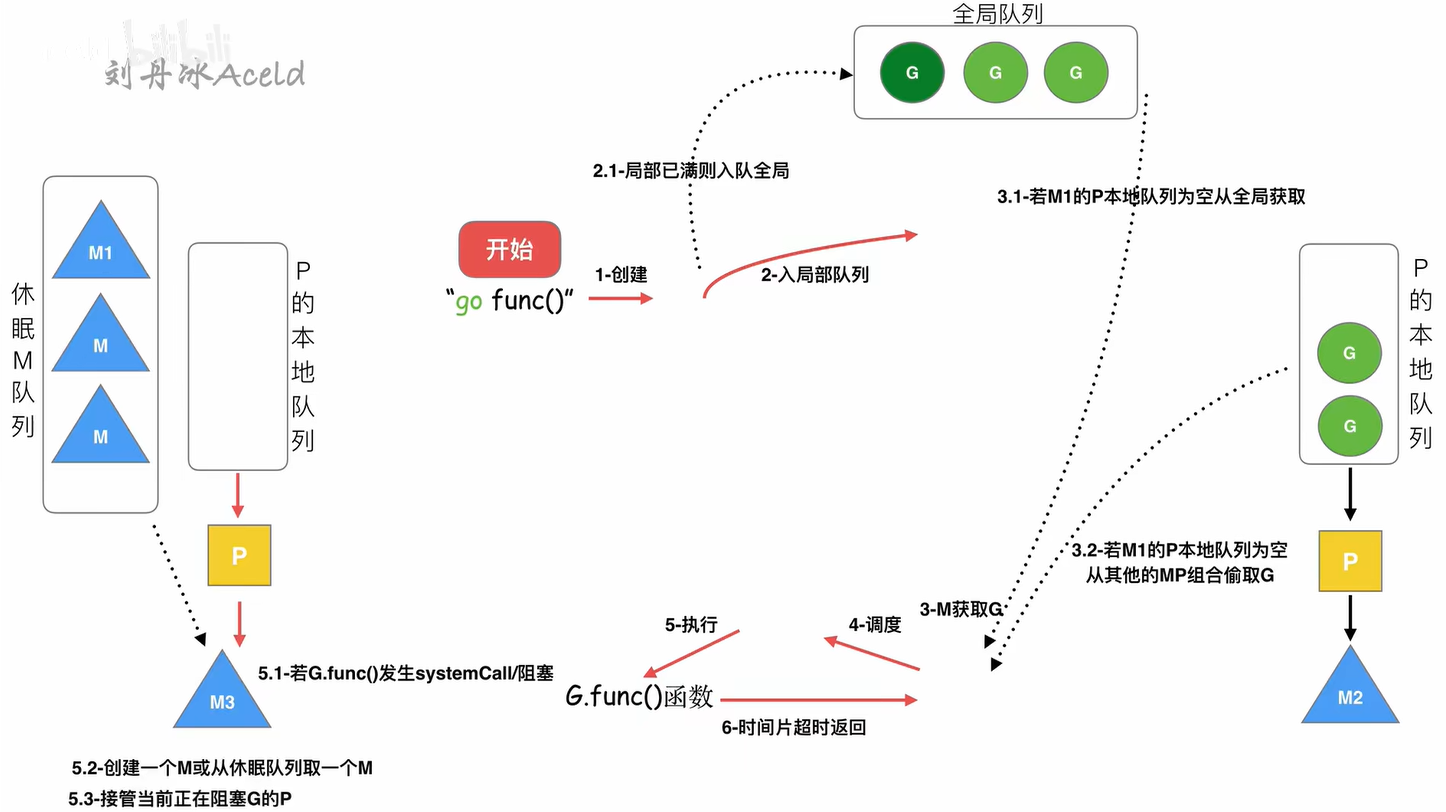
go func()命令的执行流程:
- 创建一个Goroutine
- 尝试将Goroutine放入本线程绑定的P的本地队列中,如果本地队列已满,那么就把Goroutine放入全局队列中
- M会从P的本地队列中取出一个Goroutine执行,若本地队列为空,那就从别的MP组合或全局队列中“偷”一个Goroutine执行
- M循环调度不同的G
- 当M在执行G时发生了阻塞,runtime会把这个M和P解除关联,然后创建/唤醒一个线程,接着让这个线程取服务解除关联的P
- 当M调度结束后,G会尝试获取一个空闲的P,并进入该P的本地队列中,M和P重新关联。如果获取不到,那么G会被放入全局队列,M则是加入空闲线程中,进入休眠状态
Go启动周期的M0和G0
M0:进程启动时创建的第一个线程,称为M0。M0实例会在全局变量runtime.m0中,不需要在heap中分配中间。M0负责执行一些初始化操作,接着便和普通线程无异
G0:每一个线程在被创建之后,会立即创建一个Goroutine,称为G0,即每一个线程都有一个属于自己的G0。G0不指向某个具体的函数,而是专门负责调度本地队列中的G。在调度或系统调度时,会使用G0的栈空间,全局变量G0就是M0所创建的G0
GMP可视化调试
// 创建trace.out文件
f, err := os.Create("trace.out")
if err != nil {}
// 启动trace
err = trace.Start(f)
if err != nil {}
// do something
// 这里是业务代码
// 停止trace
trace.Stop()运行程序后,会生成一个名为trace.out的文件,可以使用go tool trace $filename命令对这个文件进行可视化分析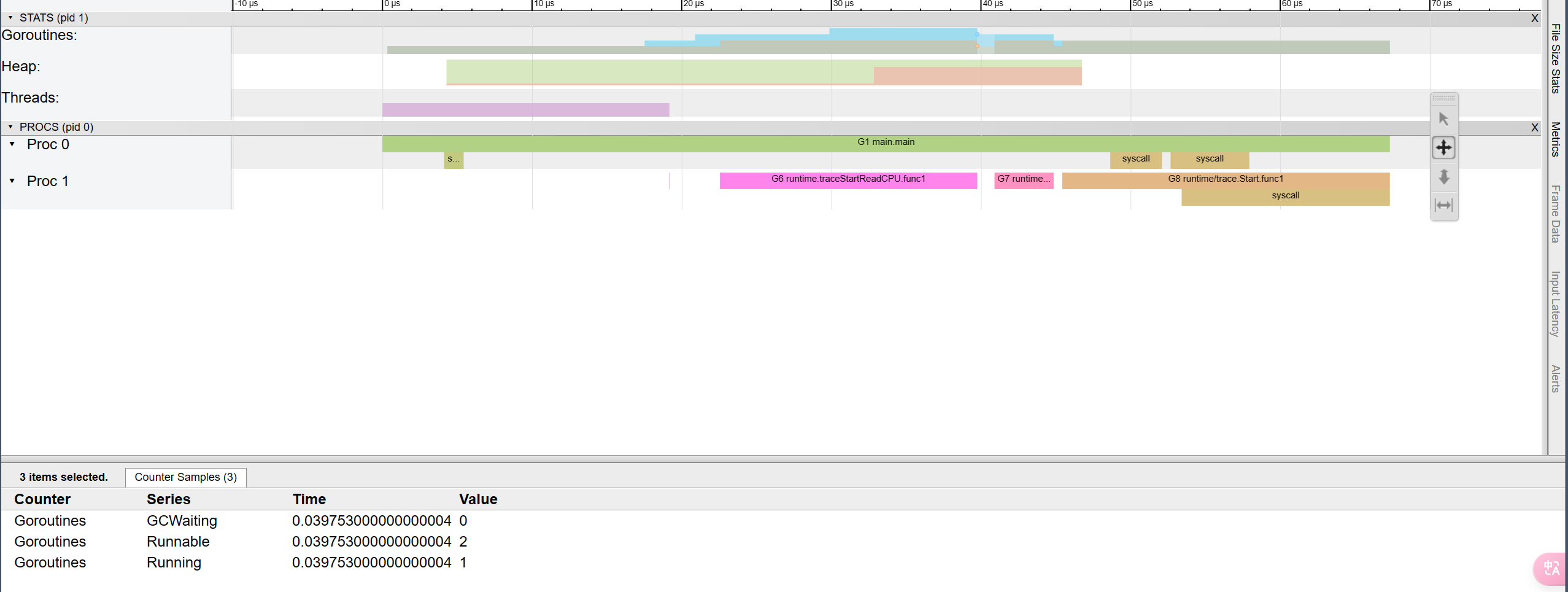
左栏自上而下依次是:G协程信息、堆栈信息、M线程信息、P调度器信息
GMP调度场景全过程分析
G1创建G’
P拥有G1,G1在运行过程中调用go fun()创建了G‘。考虑到局部性,优先将G2放入到该P的本地队列中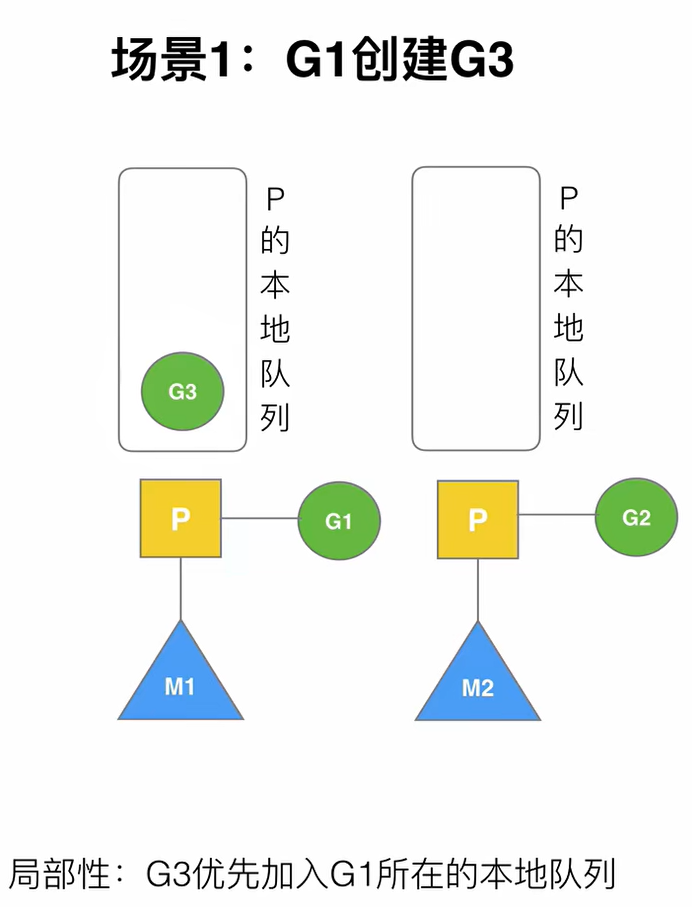
G1执行完毕
G1运行完毕后,G0切换到M上运行,G0执行调度工作(schedule函数):从P的本地队列中取出G2,M上运行的Goroutine从G0切换至G2,并开始运行G2(execute函数)。实现线程的复用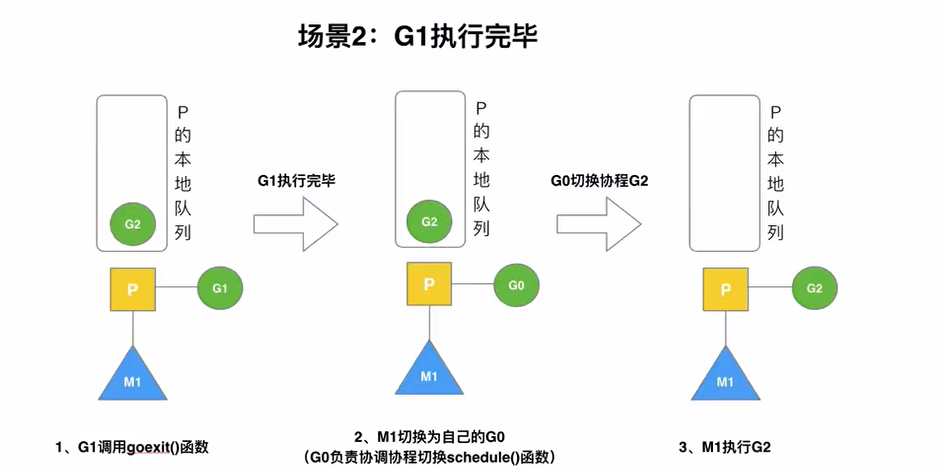
本地队列已满,再创建G
如果当前运行的G创建了一个G,恰巧P的本地队列无法再容纳新创建的G时,需要将本地队列中前半部分的G打乱顺序,连同新创建的G一起放入全局队列中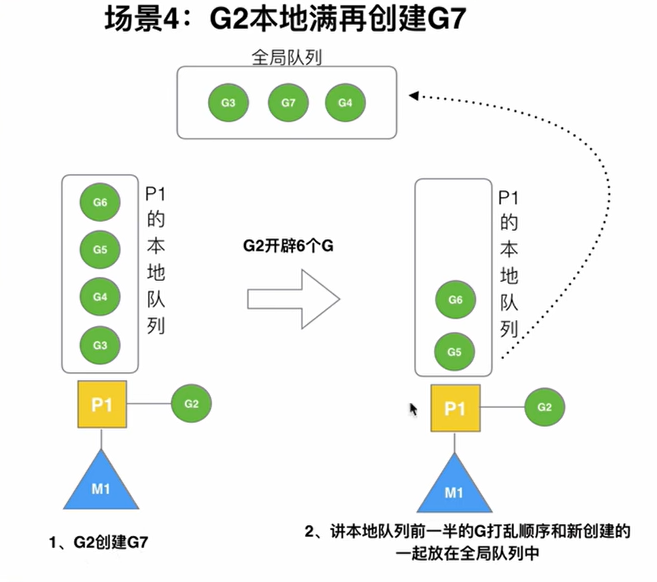
唤醒正在休眠的M
在一个G创建一个新的G时,会尝试唤醒等待队列中的M。假设唤醒了M2,M2会寻找一个空闲的P进行绑定,并运行G0,执行协程的调度。如果P的本地队列为空,那么M2亟需寻找一个G来执行,此时M2就是自旋线程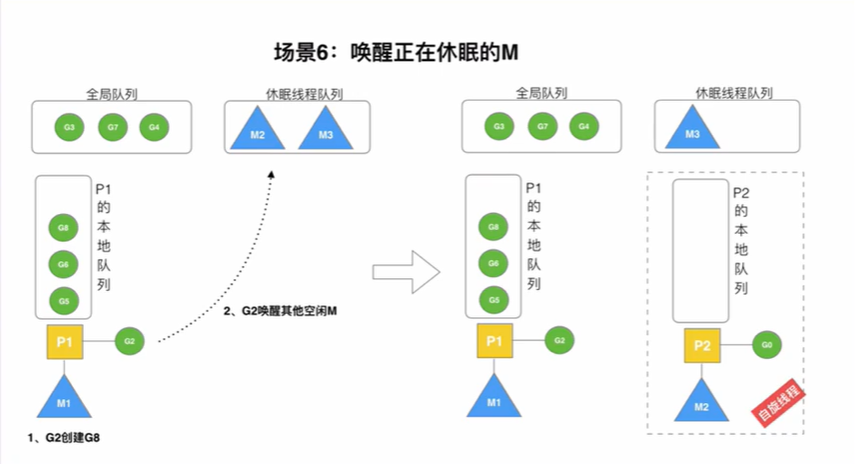
被唤醒的M2从全局队列中批量取G
自旋线程M2会尝试从全局队列中获取G执行,获取的G的数量由min(len(GQ)/2 + 1, len(GQ)/2)决定,其中len(GQ)表示全局队列中元素个数。M2批量获取G的过程叫做”从全局队列到本地队列的负载均衡“。(感觉就是为了避免拉取太多的G,一是导致本线程消化不了,二是饿死别的线程)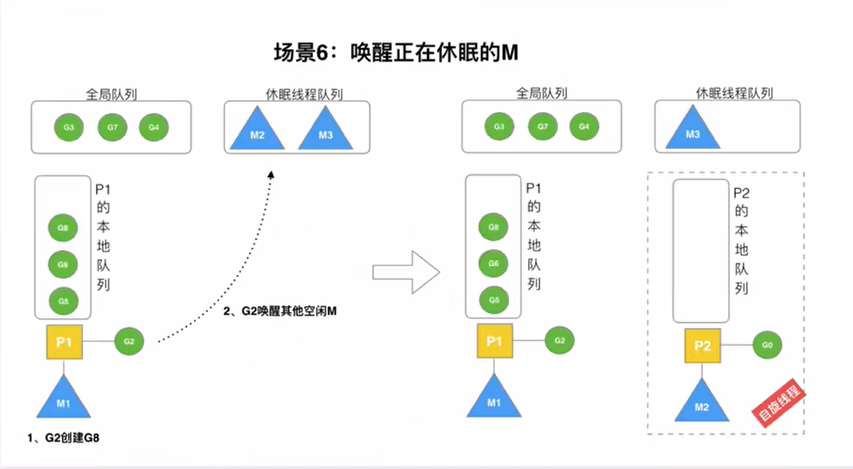
偷取M的G
如果全局队列已经没有G了,自旋线程M2就会尝试从别的线程(M1)中偷取一批G,放入本地队列中准备调度。具体地,M2会偷取,M1本地队列中后半部分的G作为本线程即将执行调度的G,下图中P1的本地队列后半部分只有G8,因此G8被M2偷取执行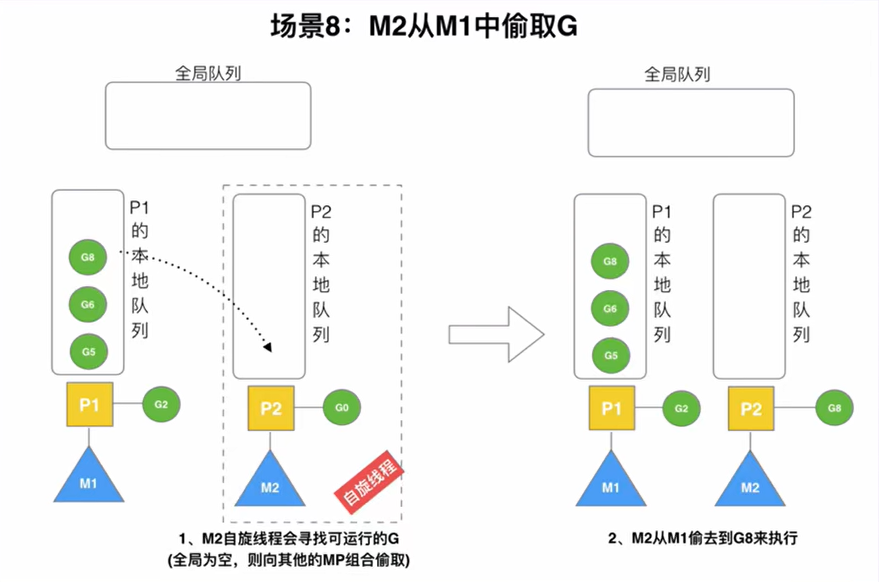
自旋线程的限制
最多有GOMAXPROCS个自旋线程,即使有再多的线程,也会因为没有空闲的P进行调度进入休眠状态
G发生调用阻塞
当G8发生了调用阻塞,P2会立即和M2解绑。接下来P2会判断是否有线程处于休眠状态,如果有,就唤醒一个线程并与之绑定,否则P2会加入空闲P列表中,等待M来获取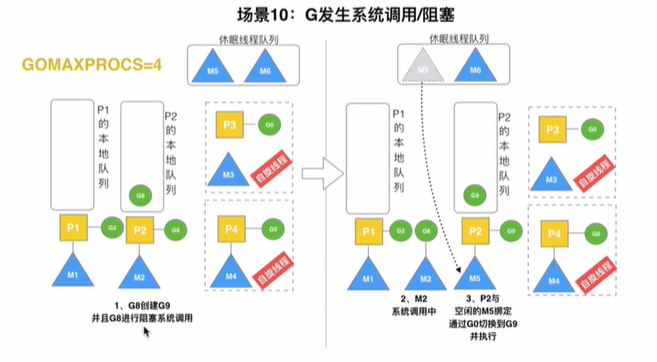
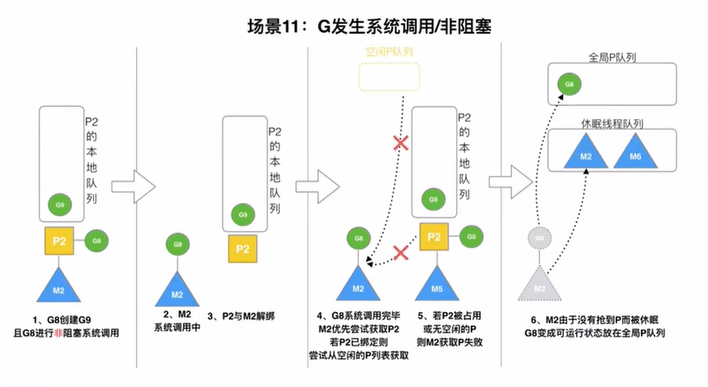
G发生系统调用/非阻塞
当G8从阻塞状态中恢复后,M2想要运行G8必须要有P的支持。那么M2会尝试重新获取P2,如果发现P2已经被绑定,就再尝试从空闲P队列中获取一个P。如果获取P失败,G8就会被放入全局队列,M2进入休眠线程队列