锁
锁类型
aba
行级锁
aba
MDL锁
aba
死锁
死锁是怎么发生的?
发生死锁的条件有哪些?
怎么排查死锁问题?
怎么避免死锁问题?
为什么会产生死锁
InnoDB默认的事务隔离级别是可重复读,在可重复读事务隔离级别下多个并发的事务可能会导致幻读问题。InnoDB为了既能保证性能(不使用串行化隔离级别)又能解决幻读问题,便提出了next-key锁,它是记录锁和间隙锁的组合
- Record key,记录锁,锁的是记录本身
- Gap key,间隙锁,锁的是两个值的间隙,防止其他事务在这个间隙中插入新的记录,从而避免幻读现象
普通的select语句使用MVCC机制实现可重复读,并不会对记录加锁,想要在查询记录时对记录加锁可以使用下列两种方式:
begin:
# 对读取的记录加共享锁
select ... lock in share mode;
commit; # 提交事务,释放锁
begin:
# 对读取的记录加
select ... for update;
commit; #怎么确定加锁类型的❓❓❓
行锁的释放时机是在事务提交之后,并不是执行完一条语句就会释放锁
⚠️:如果update语句中where条件没有使用索引列,那么就会对全表进行扫描,所有的记录都会被上行锁,记录和记录之间的间隙会被上间隙锁,也就是说,整个表都被上锁了😂,直到事务结束后才会释放。这就会导致其他事务停滞,造成极大的性能损失
- 插入意向锁和间隙锁是冲突的,所以当其他事务持有该间隙的间隙锁时,之后在这些事务提交并释放锁之后,事务A才能拿到插入意向锁。
- 而间隙锁和间隙锁之间时兼容的,即两个事务拿着的间隙锁所上锁的区间是允许有重叠部分的。
正是因为上述两个原因,在某些情况下就会有死锁发生🌰:
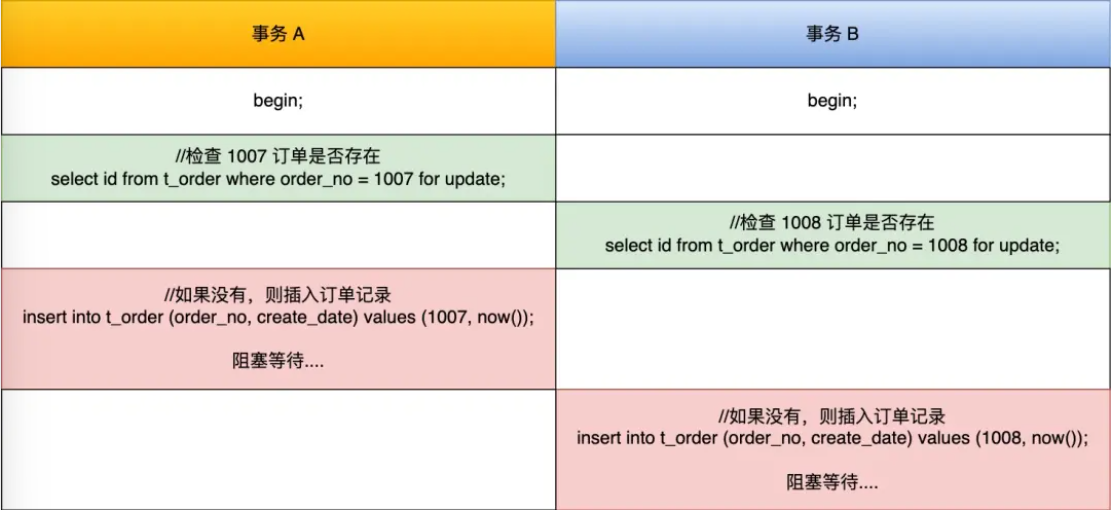
如何避免死锁
死锁产生的四个必要条件:互斥、占有并等待、非抢占、循环等待。如果系统发生了死锁,只要破环四个必要条件中的任意一个就能解除死锁
在数据库层面有两种策略打破循环等待条件来解除死锁:
- 设置事务等待锁的阈值时间:当事务等待锁的时间超过阈值,就主动进行回滚操作,将锁释放,那么另一个事务就能继续执行了
- 开启主动死锁检测:当检测到发生死锁后,主动回滚死锁链条中的一个事务,让其他事务能够正常执行
悲观锁和乐观锁
悲观锁和乐观锁
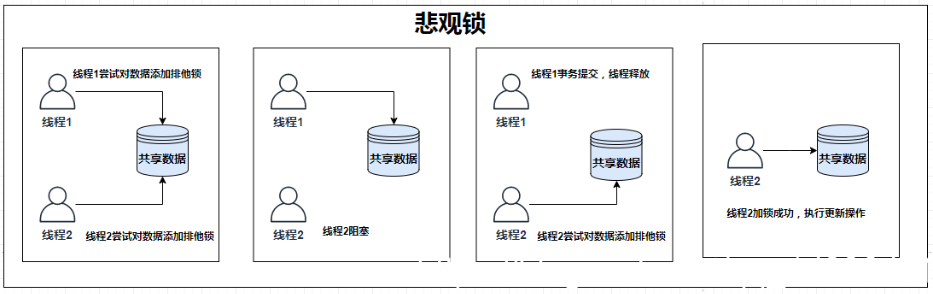
悲观锁(Pessimistic Lock):悲观地认为每拿到数据的这段时间,别的线程会对数据进行修改,所以每次拿数据直接都对数据上锁,防止别的线程拿到数据。悲观锁中的共享资源每次只给一个线程使用,其他线程则会被阻塞,直至悲观锁释放
悲观锁的并发控制实质上是采用了先上锁再访问的保守策略,保证了并发下数据安全处理,但是性能较差
乐观锁(Optimistic Lock):乐观地认为拿到数据的这段时间,别的线程不会对数据进行修改,只有在想要更新数据时才检查数据是否被别的线程更新过。如果更新过,则重新读取,并再次尝试更新,循环此步骤直至更新成功(或超时)
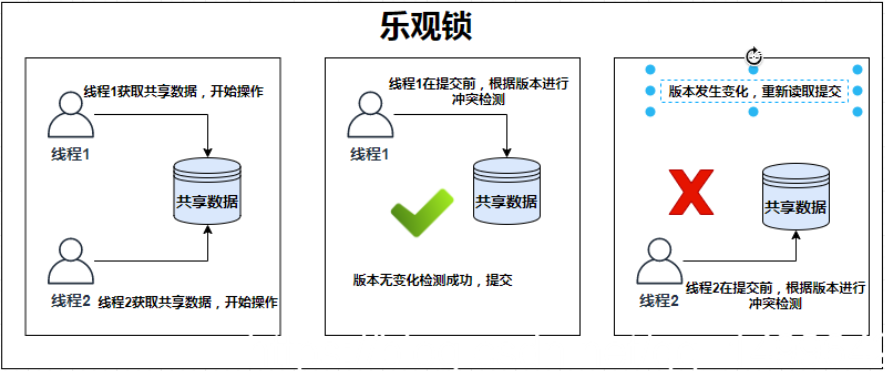
乐观锁认为发生数据竞争的概率比较小,只有在更新的时候才会进行数据校验,实际上不会上锁,所以不会产生死锁现象
CAS(compare and swap)即比较并替换
- 比较:读取到一个数据值为A,在将其更新为B之前,先检查一下原值是否仍是A
- 如果不是,则放弃更改
- 如果是,则将数据值设置为B
compare和swap两步操作是原子性的,在CPU看来就是一步操作
ABA问题:如果某个数据初值为A,但是别的线程将其改为C后又修改成了A,此时在CAS检查过程中就误认为数据并没有被修改。这个问题就是CAS中的ABA问题
ABA问题的解决:可以增加一个版本号(version)字段,每次更新操作都要对version+1,在CAS检查过程中不仅仅检查数据值还要检查版本号是否修改
⚠️:
- 乐观锁并未真正加锁,效率较高,适用于写比较少的情况,更新失败概率比较高
- 悲观锁依赖于数据库锁,效率低,更新失败概率比较低