MySQL事务学习
事务ACID
aba
事务隔离级别
事务并发会 产生什么问题?
事务隔离级别有哪些?怎么实现的?
读已提交和可重复度有什么区别?
MVCC是什么?解决了什么问题?实现原理是什么?
可重复读隔离级别彻底解决幻读了吗?
事务的四个特性,以及InnoDB引擎的实现方式:
- 原子性
- 通过undo log(回滚日志)来保证
- 一致性
- 通过持久性+原子性+隔离性来保证
- 持久性
- 通过redo log(重做日志)来保证
- 隔离性
- 通过MVCC(多版本并发控制)或锁机制来保证
并行的事务会有什么问题?
MySQL在同时处理多个事务时,可能会出现脏读、不可重复读、幻读的问题
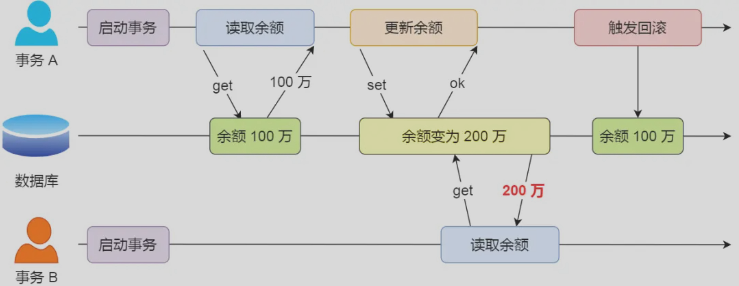
脏读
一个事务读取到了另一个未提交的事务所修改的数据,就意味着发生了脏读
🌰:事务A读取并修改账户余额为200w,但没有立刻提交事务。在这一期间,事务B读取到账户余额为200w,但是呢,由于事务A还未正式提交,仍有可能发生回滚操作,如果事务A发生了回滚,那么事务B读到的数据就是一个没用的、过期的数据,这种现象就是脏读
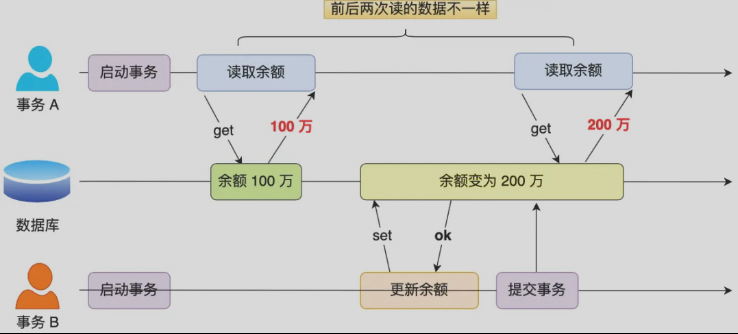
不可重复读
在一个事务内多次读取同一个数据,如果前后两次读取结果不同,就意味着发生了不可重复读
🌰:事务A有两次读取余额操作,好巧不巧🤪在这两次读取操作之间,事务B快速的修改了余额并进行了提交。结果就是,事务A第一次读取到的是原始数据,而第二次读取到的却是事务B修改过后的数据,两次数据不一致!这种现象就是不可重复读
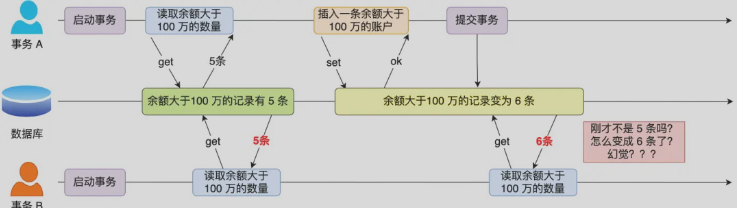
幻读
在一个事务内多次查询符合条件的记录数量,如果出现前后查询结果不同,这就说明发生了幻读
又是🌰:事务A查询完余额大于100w的记录数量为5条后,事务A打算歇一会😴。在事务A歇息的过程中,事务B悄悄的插入了一条余额大于100w的记录,导致现在共有6条记录符合查询条件。当事务A醒来再次进行查询时,就会惊讶地发现多了一条记录,那么它肯定会认为是自己睡觉睡出幻觉了🤪,这种现象就是幻读
有哪些事务的隔离级别?
由前文可知,多个事务并行处理时可以会出现脏读、不可重复读、幻读现象,这三种现象按严重性排序如下:
脏读 > 不可重复读 > 幻读
针对上述三种现象出现与否,SQL标准提出了四种事务隔离级别,事务隔离级别越高,性能越差🙃,按照隔离级别从低到高一次是:
- 读未提交:指一个事务还未提交,它所做的数据变更就能被其他事务看到
- 可能发生脏读、不可重复读、幻读
- 读提交:指一个事务只有在提交后,它所做的数据变更才能被其他事务看到
- 可能发生不可重复读、幻读
- 可重复读:指一个事务执行过程中所看到的数据在事务开始时就被确定(类似于快照📷),是InnoDB引擎的默认事务隔离级别
- 可能发生幻读
- 串行化:会对记录加上读写锁,当多个事务发生读写冲突时,后访问数据的事务必须等待前一个事务完成才能继续执行
- 木有问题,但是性能很差🤪
⚠️:MySQL的InnoDB引擎的默认事务隔离级别是「可重复读」,但它很大程度上避免了幻读现象,解决方案有两种:
- 针对快照读(普通select语句),通过MVCC方式解决幻读。因为事务执行过程中的数据在事务开始时就已经确定了,即使在A事务执行中程B事务插入了一条数据,这也对A事务是不可见的、透明的,所以就很好的避免了幻读现象
- 针对当前读(select … for update语句),通过next-key lock(记录锁+间隙锁)方式解决了幻读。因为当A事务执行
select ... for update语句时,会加上next-key lock,若事务B在锁的范围内插入了一条数据,那么事务B的插入语句会被阻塞,无法插入成功,所以就很好地解决了幻读问题
四种隔离级别的实现方式
- 读未提交
- 直接读就好了
- 串行化
- 加读写锁避免并行访问
- 读提交和可重复读都是通过Read View来实现的,区别在于创建Read View的时机
- 读提交在每一个语句执行之前都会生成一个Read View
- 可重复读只在启动事务时生成一个Read View,然后整个事务执行过程中都用这一个Read View
🌟区分「开启事务」和「启动事务」
在MySQL中有两种方式开启事务
# 第一种
begin/start transaction
# 第二种
start transaction with consistent snapshot以第一种方式开启事务不代表启动了一个事务,只有执行了第一条select语句,才是真正启动事务
第二种方式在开启事务的同时也启动了事务(毕竟命令中都带有snapshot😂)
Read View在MVCC是如何工作的?
两个前置知识
Read View中四个字段作用
聚簇索引记录中两个跟事务有关的两个隐藏字段
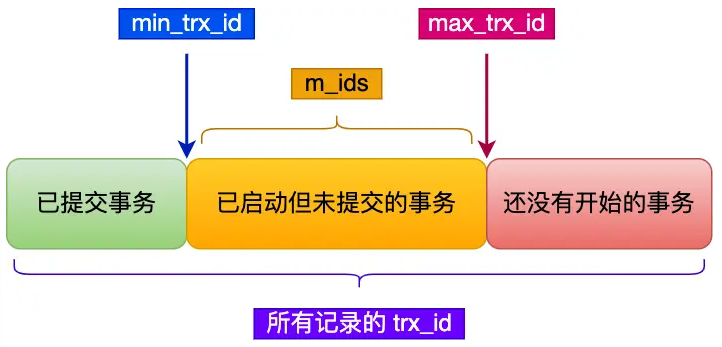
Read View实质是由四个字段构成的
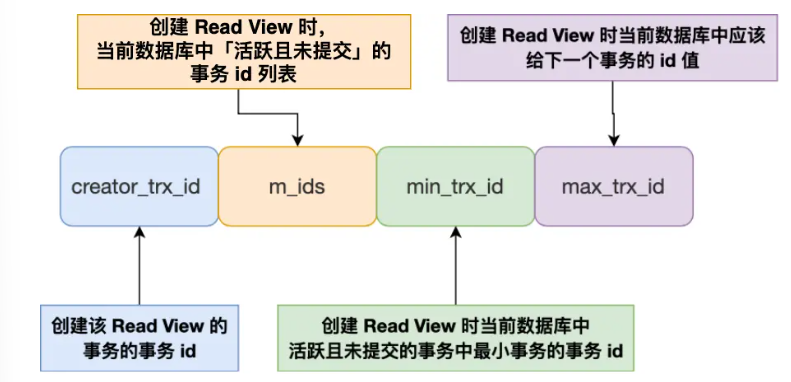
- m_ids:指在创建Read View时,当前数据库中「活跃事务」的事务id,可能有多个
- 活跃事务即启动了但是还没有提交的事务
- min_trx_id:活跃事务中最小的事务id
- max_trx_id:数据库下一个将分配给事务的id,即全局事务id的最大值+1
- creator_trx_id:创建当前Read View的事务id
了解完Read View中的四个字段后,再看看聚簇索引记录中的两个隐藏字段,🌰:
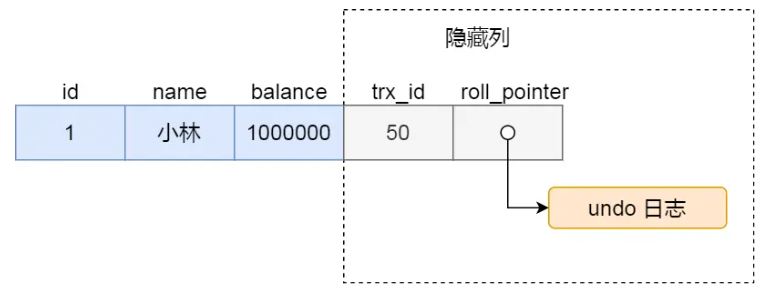
- trx_id:当一个事务对某条聚簇索引的数据进行改动时,就把该事务的id放入trx_id字段中
- roll_pointer:当对某条聚簇索引记录进行修改时,都会把旧版本的数据记录在undo日志中,roll_pointer就指向每一个旧版本的数据,因此可以通过roll_pointer隐藏列找到历史记录
MVCC
在了解Read View四个字段以及聚簇索引记录的两个隐藏列后,接下来就可以弄清楚MVCC是如何控制数据快照的
假设现在有一个「活跃事务」事务A,那么可以根据事务A的Read View创建时刻将其他事务划分为四类:
- 事务id小于
min_trx_id - 事务id大于等于
max_trx_id - 事务id在
min_trx_id和max_trx_id之间且位于m_ids中 - 事务id在
min_trx_id和max_trx_id之间且不位于m_ids中
- 如果记录的隐藏列
trx_id值小于min_trx_id,那么这个版本的记录是在Read View创建之前完成的,所以该版本记录是对当前事务可见的 - 如果
trx_id值大于等于max_trx_id,说明这个版本的记录是在Read View创建之后生成的,故对于当前事务是不可见的 - 如果
trx_id值在min_trx_id和max_trx_id之间,则需要进一步判断记录的trx_id是否在m_ids列表中(即对于的事务是否是活跃事务)- 是活跃事务,那么该该版本的记录对当前事务不可见
- 不是活跃事务,那么该版本的记录是可见的
- 🌰:创建了1、2、3、4这四个事务,其中事务3以迅雷不及掩耳之势提交了,那么随后启动的事务5是可以看见事务3所修改的记录版本的
这种通过「版本链」来控制并发事务不冲突地访问同一条记录的操作就叫MVCC(多版本并发控制)