短链系统
认识短链
短链即短链接,例如这个链接,很简短。而长链接或者叫做原始链接则有一点长,例如这个链接
可以发现,上述两个链接都跳转至同一个页面,那么有了原始链接后,为什么还要生成一个短链接?或者说短链接有什么价值🤔?
相比于原始链接,短链的优势就在于短。因此,短链在实际应用中具有如下优势:
- 简洁明了:只需要简单几个字符就能实现超长链接的跳转功能
- 便于使用
- 相同字符限制情况下,短链可以传递更多信息
- 用短链生成的二维码更容易被识别
- 节约成本:有些平台的短信服务按照字符数计费,从这个角度出发,短链可以节约成本
短链的原理
以这个短链为例子,探究短链的原理
输入curl -i http://gk.link/a/10q2I命令,其中-i表示连带相应头一同输出,结果如下图所示:
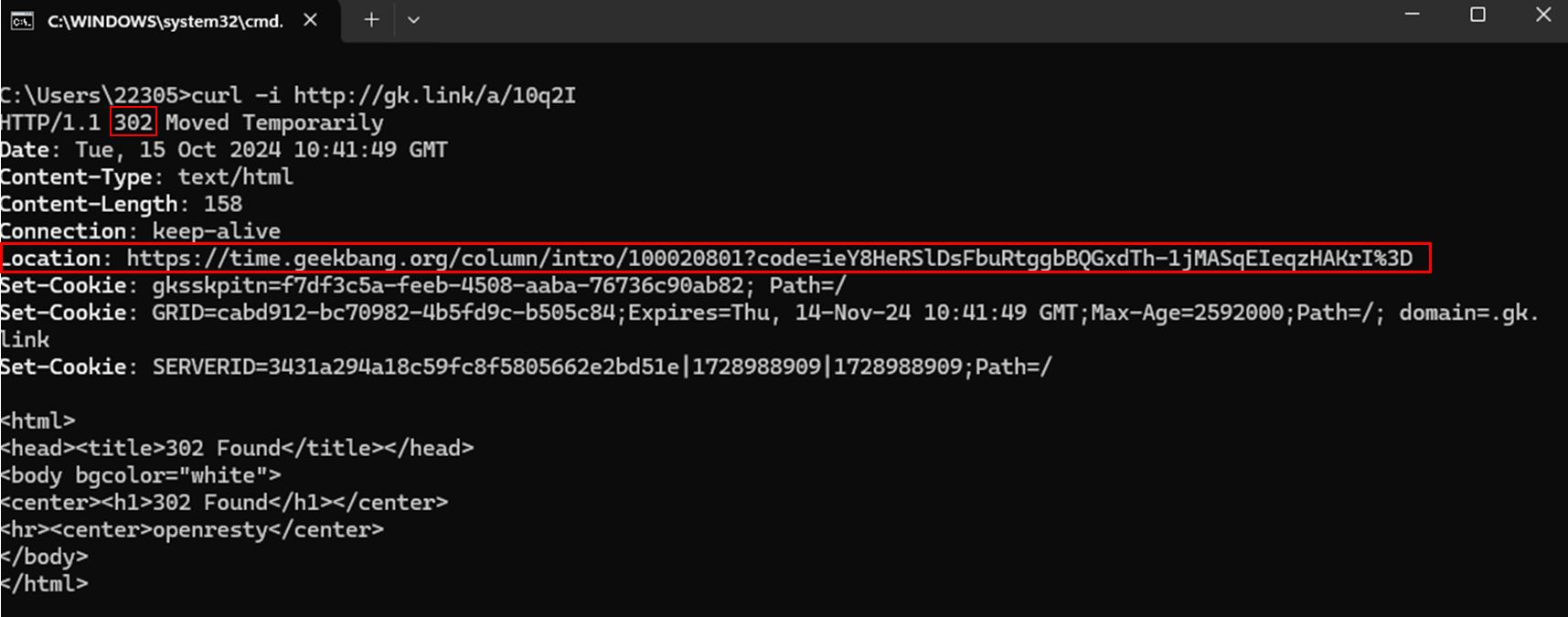
其中有两个重要信息已经被我框起来了。
相应状态码302表示临时重定向,用于告知接收方当前地址只是一个临时地址,真正的地址在Location字段中
头部字段Location代表了真正的目的地址,当接收方收到这个响应后,会取出并访问Location字段中的地址
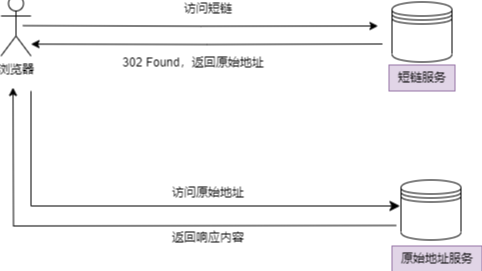
简单概括,我们访问一个极短的链接,然后重定向到原始地址(一般原始地址比短链长得多)
如何生成短链
哈希算法
很显然,短链和原始链接最好是一对一关系。那么可以将问题转换成如何为一个链接找到唯一的对应值?
一种很直接的想法:我们可以将原始链接通过一次(或多次)哈希计算,得到一个对应值。但是现如今有众多哈希算法,例如MD5、SHA-1、SHA-256,又该如何选择?
我们可以从加密程度的角度将哈希算法分为两大类:加密哈希、非加密哈希。当输入值经过加密哈希计算后,无法从输出值反推出输入值,保证了输入值的安全性,但代价是需要耗费更多的计算资源(时间)。在短链场景中,相较于原文的保密性,运算速度是我们更加关心的因素。因此,可以采用非加密哈希,例如MurmurHash,来生成短链。
使用哈希算法的场景,不可避免会出现哈希冲突问题即不同的输入值通过哈希计算时得到了相同的输出值。借鉴bcrypt加密算法中的加盐操作,当某一个输入值发生哈希冲突后,可以在添加一段特殊字符后再进行哈希运算,反复操作直至冲突消失。
/*
www.baidu.com
哈希冲突 ---> 添加特殊字符
www.baidu.com[hello_world]
*/通过哈希算法得到一个数值后,例如3510643912,我们还可以利用62进制(0-9、a-z、A-Z共62个URL合法字符)将结果进一步缩短
🌰:3510643912 —> 3PAiQU,这样我们就可以利用更短的字符串作为短链
唯一ID算法
除了使用哈希算法简化长链,还能为每一个长链请求分配一个唯一的ID,这个唯一ID就相当于哈希算法中的哈希值。当然,唯一ID也能在base62进制下进一步化简
那么现在的问题就是,如何设计一个ID分号器?
MySQL自增ID分号
通过MySQL自增主键为长链分发一个唯一ID,但这种方法存在高并发性能问题。一种解决思路是:预先为集群中的每一个服务分配一个可用的ID范围,只有当服务中可使用的ID不足时才会向数据源请求新的ID
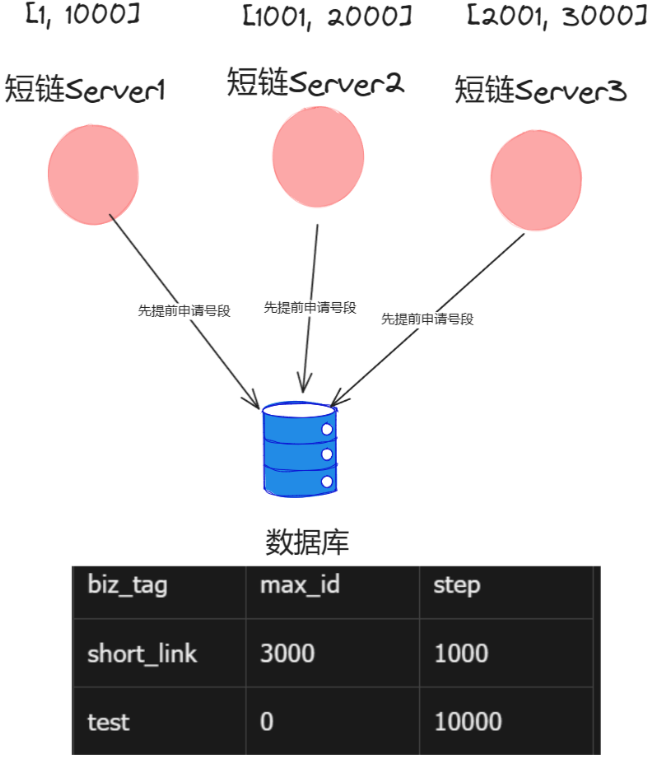
如上图所示,biz_tag表示业务类型,max_id表示当前业务可分发的最大ID,step表示步长,即每个服务一次预可申请多少个ID号码
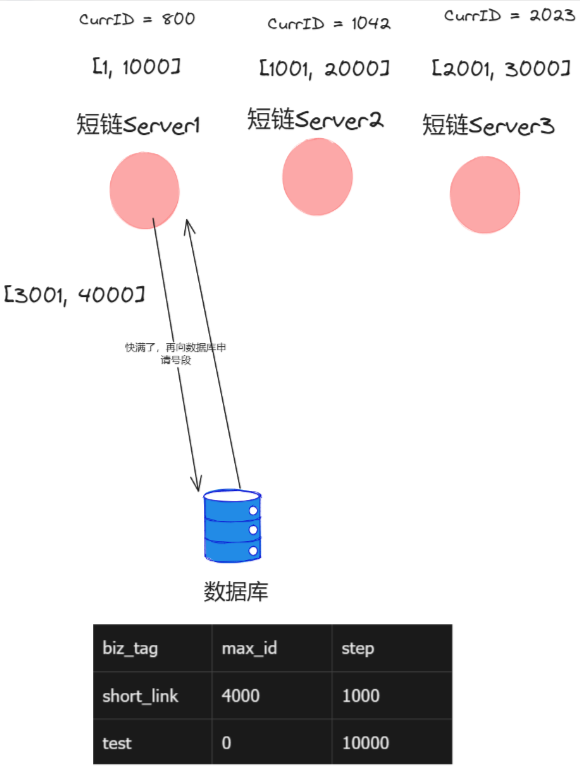
当ID不够用了,就像数据库再申请一批
此外,还可以引入队列缓冲 + 批量写入架构,在区间快满时就申请一批新的ID号码,等区间满了再一次性写入数据库中,实现异步进行获取和写入操作,保证服务持续的高并发
例如,现有10000个ID号码,当剩余的ID号不足1000时,就向数据源请求再分发10000个ID号,在上一批ID用完时,将数据批量写入数据库中
MySQL自增ID优点:
- 简单方便,容易实现
缺点:
- 整体性能吞吐量低,高并发场景下容易出现单点瓶颈
Redis自增ID
Redis基于内存实现,并发性能高(10w),但使用Redis作为分号器需要考虑持久化和灾备
优点:
- 整体吞吐量比数据好
缺点:
- Redis实例或集群宕机后,很难找回最新的ID
雪花算法生成ID
前两种方案都是远程ID生成,一般来说,远程ID生成效率(本身对应的组件耗时 + 网络耗时)不如本地ID生成。雪花算法生成ID方案就是一种本地ID方案,不依赖于其他的服务。
雪花算法使用一个long类型的整数(64位bit)来表示一个ID,具体由1bit空闲 + 41bit时间戳(毫秒级别) + 10bit机器ID(或机房ID + 机器ID) + 12bit序列号组成。
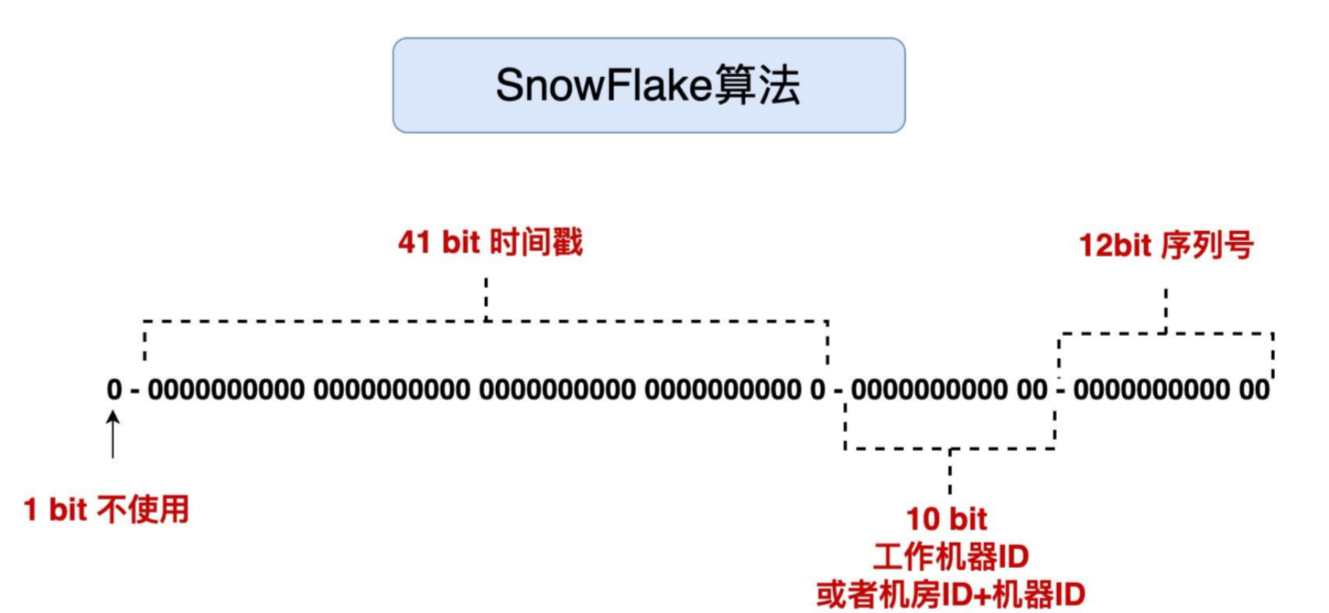
优点:
- 高性能、低延迟、去中心化、整体按时间有序
缺点:
- 要求机器时间同步在秒级别,否则会产生ID冲突
- 如果某台机器时钟回拨这有可能发生ID冲突
设计短链
重定向状态码的选择
由之前的分析我们知道了短链系统的大致工作原理:浏览器访问短链,短链服务向浏览器返回一个重定向状态码和对应的长链。接着,浏览器访问长链获取并获取到目标资源。
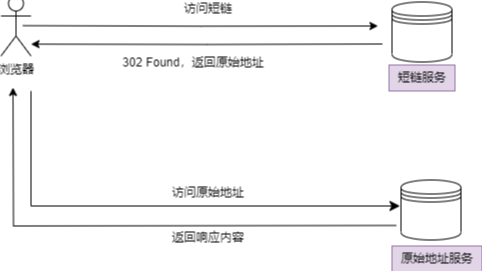
在短链系统中一般只考虑使用永久重定向301或临时重定向302状态码
两个状态码区别如下:
- 301状态码表示永久重定向,浏览器收到改状态码时,会将
Location字段值缓存在本地,当将再次访问短链时就直接从缓存中拿出长链地址并访问,节约了一次访问短链服务的次数 - 302状态码表示临时重定向,浏览器不会缓存响应头部中的
Location字段 - 在短链系统中,浏览器的缓存行为可能并非是我们预期的,尤其需要对短链进行分析的情况
- 🌰:将一个短链通过短信发送给1w个用户,如果使用302状态码就可以测试出这1w个用户针对短链的点击次数。但是在使用301状态码情况下,每一个用户最多只会被统计一次。(因为浏览器缓存了长链地址)